
Worksheet 3-1#
Note
This jupyter notebook won’t run on the website. If you are viewing this online, click on the download (down arrow) button on the top right of the page, select the .ipynb option, and save the file locally. Then open it with your Jupyter system to edit the file.
✅ Put your name here.
✅ Put your group number here.
Topics covered#
This notebook covers Chapter 3.1 and 3.2 from the textbook
Overdetermined systems for least squares probelms
Data fitting
Curve fitting from least squares
%matplotlib inline
import matplotlib.pylab as plt
import numpy as np
Overdetermined systems#
We are given a linear system of the form \(\mathbf{A}\mathbf{x}=\mathbf{b},\) where \(\mathbf{A}\in\mathbb{R}^{m\times n}\) and \(\mathbf{b}\in\mathbb{R}^m\).
The system is overdetermined meaning that \(m>n\).
In addition, we assume that \(\mathbf{A}\) has full column rank, i.e., \(\mathrm{rank}(\mathbf{A})=n\).
We will consider the linear system
which can be written in the form \(\mathbf{A}\mathbf{x}=\mathbf{b}\) as
A = np.array([[1, 2], [2, 1], [3, 2]])
b = np.array([0, 1, 1])
❓❓❓ Question ❓❓❓:
What are \(m\) and \(n\) for this \(A\)? Save them below.
What is the rank of the matrix? Use
np.linalg.matrix_rankto determine this.Is the matrix full rank? That is, is the rank the same as
min(m,n)?Is the matrix, overdetermined, determined, or underdetermined?
## Your answer here
m = None
n = None
rk_A = None
Solving the OLS problem#
In general, when \(m>n\) and \(\mathrm{rank}(\mathbf{A})=𝑛\), we may not find a solution \(\mathbf{x}\) for the linear system (Why?). Instead, we try to find an approximate solution by optimizing
If there is a solution to the linear system, we will also find the solution by solving the optimization problem. So we will consider \(m\geq n\) in the rest of this lecture.
Let
We can expand this to see that
❓❓❓ Question ❓❓❓: So that we don’t mix up \(A\)’s and \(b\)’s, I can write the quadratic form of a function as
where \(\mathbf{Q}\) is symmetric.
What are \(\mathbf{Q}\) and \(\mathbf{d}\) for our function above? Check that \(Q\) is symmetric.
✎ Answer here.
Solution
\(\mathbf{Q} = \mathbf{A}\mathbf{A}^\top\)
\(\mathbf{d}^\top = -\mathbf{b}^\top \mathbf{A}\), so taking transposes we have \(\mathbf{d} = -\mathbf{A}^\top \mathbf{b}\).
Since we know that \(f\) is in quadratic form, we can use that quadratic functions have
to get
and
Because \(\mathbf{A}\) is of full column rank, we have \(\mathbf{A}^\top\mathbf{A}\) is positive definite. Therefore, by properties of quadratic functions from last class, the unique solution to the optimization problem \(\min_{\mathbf{x}\in\mathbb{R}^{n}}\|\mathbf{A}\mathbf{x}-\mathbf{b}\|^2\) is obtained at \(\mathbf{x} = \mathbf{Q}^{-1}\mathbf{d}\), which translates here to
This vector is called the least squares solution or the least squares estimate of the system \(\mathbf{A}\mathbf{x}=\mathbf{b}\).
We also write in the solution as
which is called the normal system.
Example Let’s go back to the same example we were using above,
❓❓❓ Question ❓❓❓: Use numpy to find \(\mathbf{x}_{LS}=(\mathbf{A}^\top\mathbf{A})^{-1}\mathbf{A}^\top\mathbf{b}\).
## Your work here
A = np.array([[1, 2], [2, 1], [3, 2]])
b = np.array([0, 1, 1])
❓❓❓ Question ❓❓❓:
Now use the numpy command np.linalg.lstsq to get (hopefully) the same answer.
# Uncomment the line below to show information about the lstsq function.
# ?np.linalg.lstsq
# Your answer here
Data Fitting#
One application of least squares is data fitting. Suppose that we are given a set of data points \((\mathbf{s}_i,t_i)\), \(i=1,2,\dots,m\), where \(\mathbf{s}_i\in\mathbb{R}^n\) and \(t_i\in\mathbb{R}\). We assume that the target \(t_i\) can be approximated by the linear transformation of the data \(\mathbf{s}_i\). That is
Then least squares is applied to find the parameter vector \(\mathbf{x}\) that solves the following optimization problem: $\(\min_{\mathbf{x}\in\mathbb{R}^{n}}\sum_{i=1}^m(\mathbf{s}_i^\top\mathbf{x}-t_i)^2.\)$
Warning! If we’re thinking of this as learning linear transformations of the data, the \(S\) is acting as our input point, the \(x\)’s are the coefficients of the transformation, and the \(t\) is the output.
Linear fitting#
Let’s assume we want to have a linear function of a single input variable. To avoid getting in the way of our own letters, let’s say this linear function is \(t = ms+b\), where \(s\) is my input data coordinate and \(t\) is my output data coordinate. Then if we are given data points \((s_i,t_i)\), our goal is to find \(m\) and \(b\) so that
Lining up with above, we have matrices
According to what we figured out above, the minimization problem \(\min_{\mathbf{x}\in\mathbb{R}^{n}}\|\mathbf{S}\mathbf{x}-\mathbf{t}\|^2\) is solved at
Warning! Ok, just to be sure we’re all on the same page, the entries of \(\mathbf{x}\) are the COEFFICIENTS of the linear problem we’re trying to solve. But since we’re optimizing over those possible choices of coefficients, we tend to call it \(\mathbf{x}\).
Example#
I’m going to generate some data for us to play with. It actually comes from a cubic but lets pretend we don’t know that yet.
data_x = np.linspace(0, 1, 30)
data_y = (data_x-.1)*(data_x-.4)*(data_x-.8) + 0.01 * np.random.randn(30)
Write code below to make a scatter plot with the x data on the x-axis and the y data on the y-axis.
## Write code below. ##
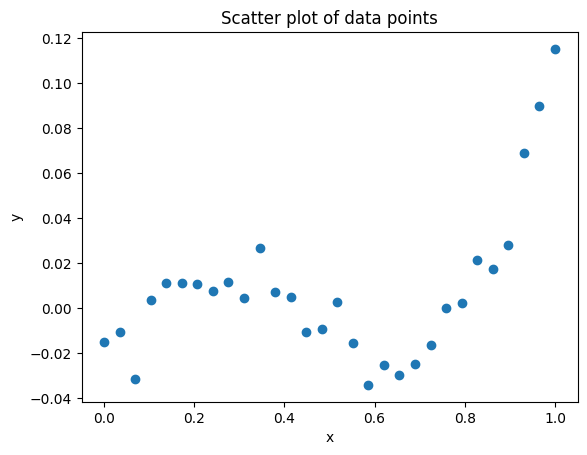
❓❓❓ Question ❓❓❓: Based on the data_x generated above, build the matrices \(\mathbf{S}\) and \(\mathbf{t}\).
# Your answer here, replace the Nones below
S = None
t = None
❓❓❓ Question ❓❓❓: Use your matrices \(\mathbf{S}\) and \(\mathbf{t}\) from above to solve the least squares problem \(\min_{\mathbf{x}\in\mathbb{R}^{n}}\|\mathbf{S}\mathbf{x}-\mathbf{t}\|^2\).
# Your answer here
❓❓❓ Question ❓❓❓: Based on the output above, determine \(m\) and \(b\) from the equation \(s_i \approx mt_i + b\) and then plug them in below to plot the line you learned on top of the data.
m = 0 #<- Fix this
b = 0 #<- Fix this too!
plt.plot(data_x, m*data_x + b, color='purple', label='Least Squares Fit Line')
plt.scatter(data_x, data_y, label = 'data')
plt.xlabel('x')
plt.ylabel('y')
plt.legend();
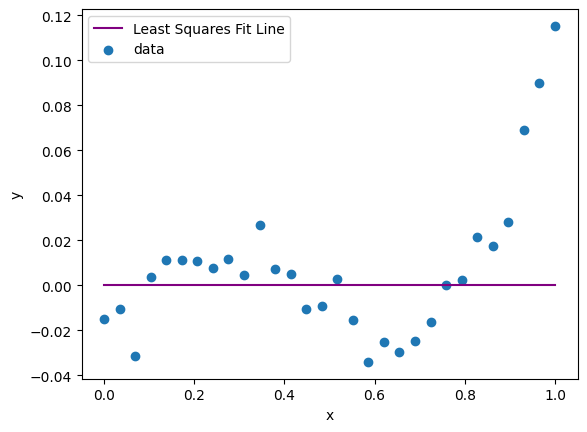
Whelp, that fit isn’t great, but we knew that we didn’t get the data from a line anyway so we didn’t expect a line to do a good job. So, let’s try to fit it with a polynomial instead.
Nonlinear fitting.#
Least squares can also be used in polynomial fitting. If we know that the points are approximately related to a polynomial of degree at most \(d\), i.e. for each data point \((s_i,t_i)\),
then for our input data, we can try to find \(\beta_i\)’s to make
Notice that the first two columns of \(\mathbf{S}\) matrix are the same as the \(S\) you figured out above. This matrix is called the Vandermonde matrix, so we can just use built in tools to compute it.
S = np.vander(data_x, N=4, increasing=True)
S[:10,:]
array([[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[1.00000000e+00, 3.44827586e-02, 1.18906064e-03, 4.10020911e-05],
[1.00000000e+00, 6.89655172e-02, 4.75624257e-03, 3.28016729e-04],
[1.00000000e+00, 1.03448276e-01, 1.07015458e-02, 1.10705646e-03],
[1.00000000e+00, 1.37931034e-01, 1.90249703e-02, 2.62413383e-03],
[1.00000000e+00, 1.72413793e-01, 2.97265161e-02, 5.12526139e-03],
[1.00000000e+00, 2.06896552e-01, 4.28061831e-02, 8.85645168e-03],
[1.00000000e+00, 2.41379310e-01, 5.82639715e-02, 1.40637172e-02],
[1.00000000e+00, 2.75862069e-01, 7.60998811e-02, 2.09930706e-02],
[1.00000000e+00, 3.10344828e-01, 9.63139120e-02, 2.98905244e-02]])
❓❓❓ Question ❓❓❓:
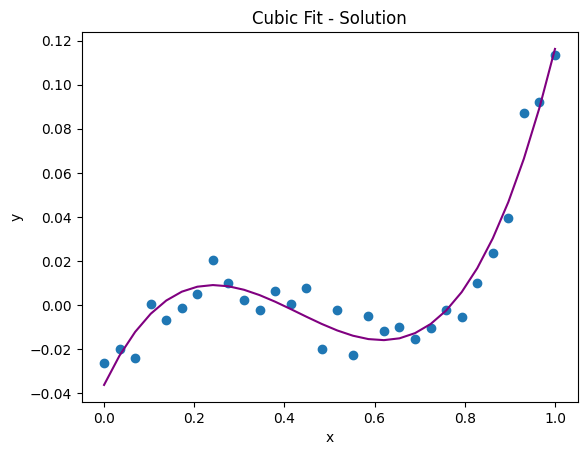
Use the new, bigger \(\mathbf{S}\) matrix to solve for the coefficients to fit a cubic polynomial, \(t = \beta_0 + \beta_1 s + \beta_2 s^2 + \beta_3s^3\). Hint: You should be able to use exactly the same code as above!
Then, update the coefficients in the plotting cell below. Does this look like a good fit now?
### Enter your code below.
# Fix these with the solution you found to see if the plotted line fits well.
beta_0 = 0
beta_1 = 0
beta_2 = 0
beta_3 = 0
plt.scatter(data_x, data_y, label = 'data')
plt.xlabel('x')
plt.ylabel('y')
plt.plot(data_x, beta_0 + beta_1*data_x + beta_2*data_x**2 + beta_3*data_x**3, color='purple', label='Cubic Least Squares Fit Line');
plt.title('Cubic Fit')
Text(0.5, 1.0, 'Cubic Fit')
Choosing \(d\)#
Now, we can try different choices of polynomial degree and see which one fits the best.
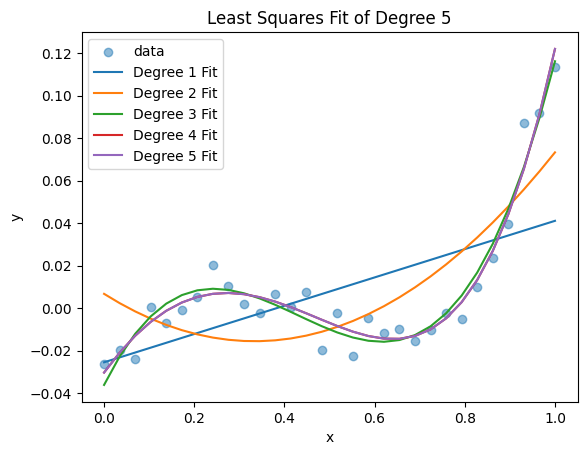
❓❓❓ Question ❓❓❓:
For \(d=1,2,3,4,5\), solve the optimzation problem above and compute the minimum value of the RSS.
Based on this, which degree polynomial gave the best approximation?
Plot all of your functions on a scatter plot of the data. Does the visually best fit function match with what you said above?
# Your code here
© Copyright 2025, The Department of Computational Mathematics, Science and Engineering at Michigan State University.