Jupyter Notebook#
Lecture 25: Random Forests#

In this module we are going to set up random forest models.
# Everyone's favorite standard imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import time
# ML imports we've used previously
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
Loading the data#
Since we’re doing regression trees, again, we’re going to use the Carseat data where we will predict Sales from the rest of the columns. I’ll do a bit of cleanup for you so we can get to the good stuff.
url = "https://msu-cmse-courses.github.io/CMSE381-S26/_downloads/2cec98f7fc943558992925bc2510bb9d/Carseats.csv"
carseats = pd.read_csv(url).drop('Unnamed: 0', axis=1)
carseats.ShelveLoc = pd.factorize(carseats.ShelveLoc)[0]
carseats.Urban = carseats.Urban.map({'No':0, 'Yes':1})
carseats.US = carseats.US.map({'No':0, 'Yes':1})
carseats.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 400 entries, 0 to 399
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Sales 400 non-null float64
1 CompPrice 400 non-null int64
2 Income 400 non-null int64
3 Advertising 400 non-null int64
4 Population 400 non-null int64
5 Price 400 non-null int64
6 ShelveLoc 400 non-null int64
7 Age 400 non-null int64
8 Education 400 non-null int64
9 Urban 400 non-null int64
10 US 400 non-null int64
dtypes: float64(1), int64(10)
memory usage: 34.5 KB
X = carseats.drop(['Sales'], axis = 1)
y = carseats.Sales
X.head()
| CompPrice | Income | Advertising | Population | Price | ShelveLoc | Age | Education | Urban | US | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 138 | 73 | 11 | 276 | 120 | 0 | 42 | 17 | 1 | 1 |
| 1 | 111 | 48 | 16 | 260 | 83 | 1 | 65 | 10 | 1 | 1 |
| 2 | 113 | 35 | 10 | 269 | 80 | 2 | 59 | 12 | 1 | 1 |
| 3 | 117 | 100 | 4 | 466 | 97 | 2 | 55 | 14 | 1 | 1 |
| 4 | 141 | 64 | 3 | 340 | 128 | 0 | 38 | 13 | 1 | 0 |
Bagging#
Last time, we figured out how to use sklearn.tree.DecisionTreeRegressor to build a single tree to do our regression, but we’d like to be able to use ensemble models to create a pile of trees to give a more robust predction.
Let’s try doing this the hard way first. We’re going to set up the bagging on our carseats data. We’ll use \(B=3\) to create our bagged model. So, step one is to generate three bootstrap samples, meaning I generate data sets by sampling \(n=400\) points with replacement.
X1 = carseats.sample(frac = 1, replace = True, random_state = 42)
y1 = X1.Sales
X1 = X1.drop(['Sales'], axis = 1)
X2 = carseats.sample(frac = 1, replace = True, random_state = 43)
y2 = X2.Sales
X2 = X2.drop(['Sales'], axis = 1)
X3 = carseats.sample(frac = 1, replace = True, random_state = 44)
y3 = X3.Sales
X3 = X3.drop(['Sales'], axis = 1)
✅ Do this: Fit one regression tree of depth 2 per sampled data we just created. You’ll end up with three regression trees: call them reg_tree1, reg_tree2, and reg_tree3. How similar are the tree structures?
from sklearn import tree
from sklearn.tree import DecisionTreeRegressor
# Your code to generate the three trees here #
# If you named your models reg_tree1, reg_tree2, and reg_tree3 above,
# this block will plot the three trees
fig, axs = plt.subplots(3,1, figsize = (20,30))
for i, reg_treeX in enumerate([reg_tree1, reg_tree2, reg_tree3]):
_= tree.plot_tree(reg_treeX, feature_names = X.columns,
filled = True,
fontsize = 22,
ax = axs[i])
axs[i].set_title(f"Tree {i+1}", fontsize = 30)
plt.show()
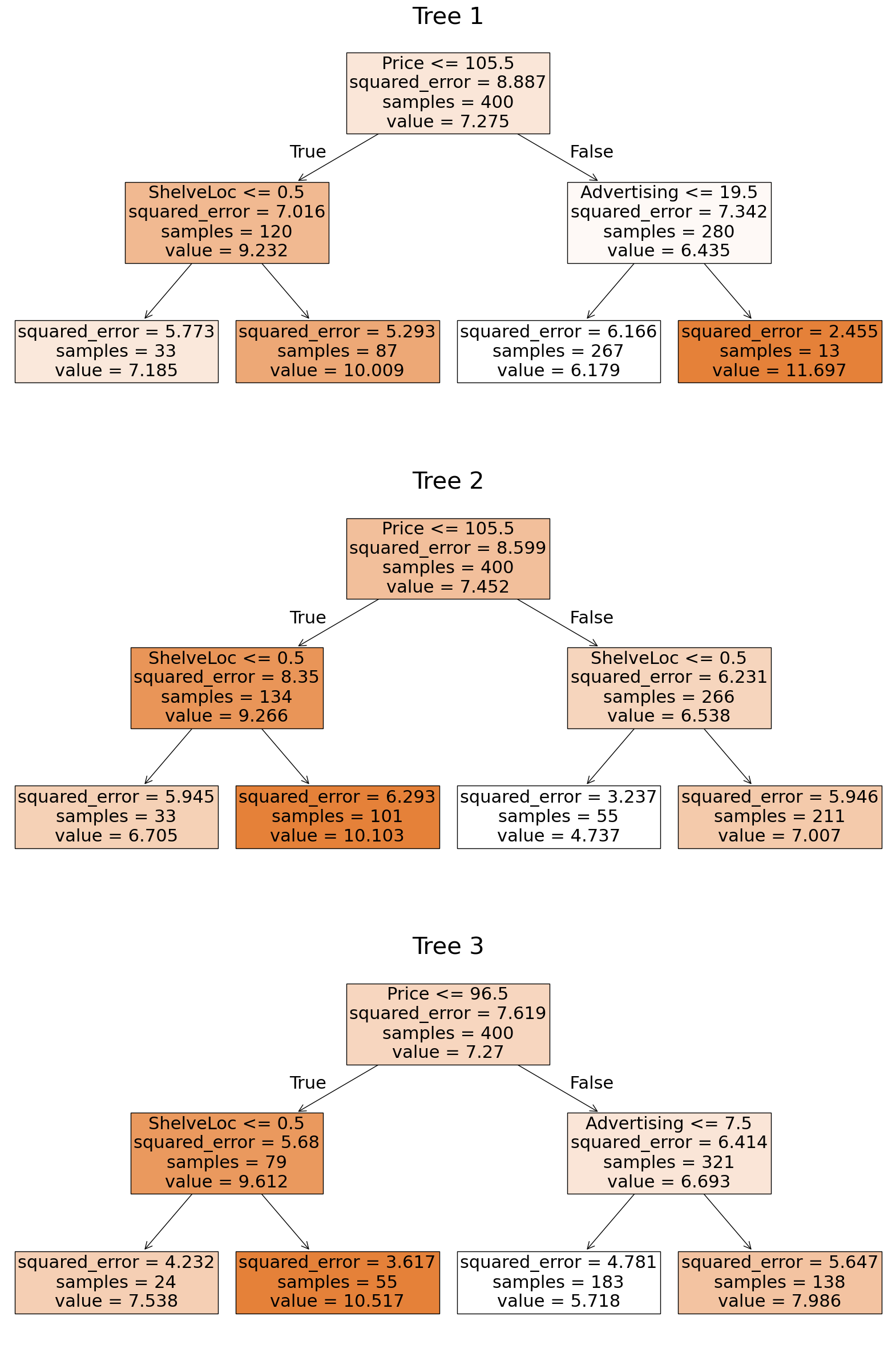
✅ Do this: Predict the Sales value for the first data point in the carseats data set using each of the three trees just generated. What is the average value of the three numbers? This is the bagged prediction for this input data.
X.head().iloc[0,:]
CompPrice 138
Income 73
Advertising 11
Population 276
Price 120
ShelveLoc 0
Age 42
Education 17
Urban 1
US 1
Name: 0, dtype: int64
# Your code to get the bagged prediction for the first here.

Great, you got to here! Hang out for a bit, there’s more lecture before we go on to the next portion.
Random Forests#
Did you really need to do all that bagging by hand? Well, no actually, but this goes under the “eating your vegetables exactly once” part of the lab. Of course, sklearn has built in functions to do bagging for us. In reality, it just has a random forest function, but if we really want to do bagging, we can cheat.
Remember, for random forests, we essentially do bagging but we only allow for a subset of \(m \leq p\) variables to be considered at each splitting step. So if we want bagging, we set the \(m=\)max_features to be the total number of features. That means this next code actually replecates what we just did above with bagging.
from sklearn.ensemble import RandomForestRegressor
# Note we have p=10 input variables
print(X.shape)
(400, 10)
bagged_carseats = RandomForestRegressor(max_features = 10, oob_score = True )
bagged_carseats.fit(X,y)
RandomForestRegressor(max_features=10, oob_score=True)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
✅ Do this: Build a random forest model instead where the maximum number of features used at each step is \(m = \sqrt {p}\).
# Your code here #
Because we have that oob_score = True set, we get access to the out of bag predictions (i.e., \(\hat y\)) from forest_carseats.oob_prediction_. That is, for each data point, predict its \(\hat y\) by returning the averaged value using only the trees it wasn’t involved in fitting.
##ANSWER##
print(forest_carseats.oob_prediction_.shape)
print(y.shape)
# forest_carseats.oob_prediction_
(400,)
(400,)
✅ Do this: Determine the OOB error on the forest model you built just above using the mean_squared_error command.
Note: The class does also keep track of the oob score as model.oob_score_, however this appears to be reporting \(R^2\) (where close to 1 is better) and I don’t seem to have the ability to change this. See the documentation for further details.
# Your code here
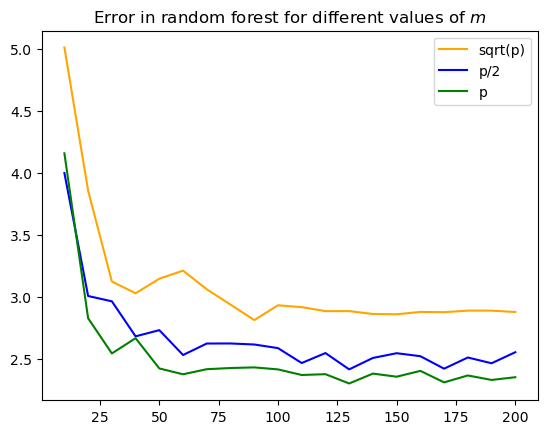
✅ Do this: How does the number of trees used (n_estimators in this code) affect the error? Generate a plot like Fig 8.10 in the book for our carseats data. How many trees should we use?
# Modify the code below to fit a bunch of models and keep track of the MSE.
p = 10
m_list = [int(np.sqrt(p)), int(p/2), int(p)]
print('m_list:', m_list)
n_tree_list = np.arange(10,201,10)
Errors = []
for m in m_list:
M_error = []
for i in range(len(n_tree_list)):
n_trees = n_tree_list[i]
#--------------------------------------------------
# Add code here to train a random forest model with
# max_features = m, n_estimators = n_trees,
# and the MSE saved as the error below.
error = 0 # <----- your error goes here.
#--------------------------------------------------
M_error.append(error)
Errors.append(np.array(M_error))
m_list: [3, 5, 10]
# If your code above works, below you'll get a plot of the different choices of m
colors = ['orange','blue','green']
labels = ['sqrt(p)', 'p/2', 'p']
for i in range(3):
M_error = Errors[i]
plt.plot(n_tree_list, M_error, label = labels[i], color = colors[i])
plt.legend()
plt.title('Error in random forest for different values of $m$')
plt.show()
Congratulations, we’re done!#
Initially created by Dr. Liz Munch, modified by Dr. Lianzhang Bao and Dr. Firas Khasawneh, Michigan State University

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.