Week 11: In-Class Assignment:
Manifold Learning#
✅ Put your name here.#
✅ Put your group member names here.
This ICA is due at 11:59PM today.
Goals of this assignment#
In this ICA you will explore two very different methods for Non-Linear Dimensionality Reduction NLDR:
Since you are teaching yourself manifold learning techniques, read a bit about these so that you have a bit of intuition for what they do.
Part 1: Make CMSE#
We will first make a dataset using an image that we create. Of course, we could use the make_s_curve or make_swiss_roll in sklearn, but that’s less fun!
Let’s make our own shapes! You can make your own custom datasets from PNG images. You don’t need to understand how the next few cells work, but feel free to read through them if you want to use this idea in your other projects.
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.image import imread
from mpl_toolkits import mplot3d
import seaborn as sns
sns.set_context("notebook")
# We will make our data from an image. This function makes a PNG file,
# reads it back in and makes a dataset from it. (Idea credit: Jake Vanderplos)
def make_cmse(N=100, rseed=42):
# Make a PNG file with "CMSE!!" text.
fig, ax = plt.subplots(figsize=(5, 1))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1)
ax.axis('off')
ax.text(0.5, 0.4, 'CMSE!', va='center', ha='center', weight='bold', size=85)
fig.savefig('cmse.png')
plt.close(fig)
# Next, with the PNG made, read the image in to make data from it.
# imread docs: https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.imread.html
img = imread('cmse.png')
data = img[::-1, :, 1].T
# Create a random number generator
rng = np.random.RandomState(42)
# Create 4*N uniform random points in the range [0 to 1)
X = rng.rand(4 * N, 2)
# Create two arrays of N elements whose values correspond to indices in the image matrix.
# Try printing the max and min values of i and j to see what they are.
i, j = (X * data.shape).astype(int).T
# Find 4*N values in the image matrix that are less than a little more than the minimum (i.e. black color)
mask = (data[i, j] < data.min() + 0.1)
# create the dataset from the image
X = X[mask]
# aspect ratio
X[:, 0] *= (data.shape[0] / data.shape[1])
# Select only the first N points
X = X[:N]
return X[np.argsort(X[:, 0])]
With that function, we can create our dataset.
X = make_cmse(2000)
print("Here is the image that was made:")
from IPython.display import Image
Image("cmse.png")
Here is the image that was made:

print("Here is the dataset made from that image:")
# set up **kwargs to control the color pattern
colorize = dict(c=X[:, 0], cmap=plt.cm.get_cmap('terrain', 5))
# use the color pattern dictionary to show the "data"
fig = plt.figure(figsize=(14,8))
plt.scatter(X[:, 0], X[:, 1], s=70, edgecolors='black', **colorize)
plt.axis('equal');
Here is the dataset made from that image:
/var/folders/cq/63hr2pgs2m1_z45dj0_n28wm0000gp/T/ipykernel_85001/2307471671.py:3: MatplotlibDeprecationWarning: The get_cmap function was deprecated in Matplotlib 3.7 and will be removed two minor releases later. Use ``matplotlib.colormaps[name]`` or ``matplotlib.colormaps.get_cmap(obj)`` instead.
colorize = dict(c=X[:, 0], cmap=plt.cm.get_cmap('terrain', 5))
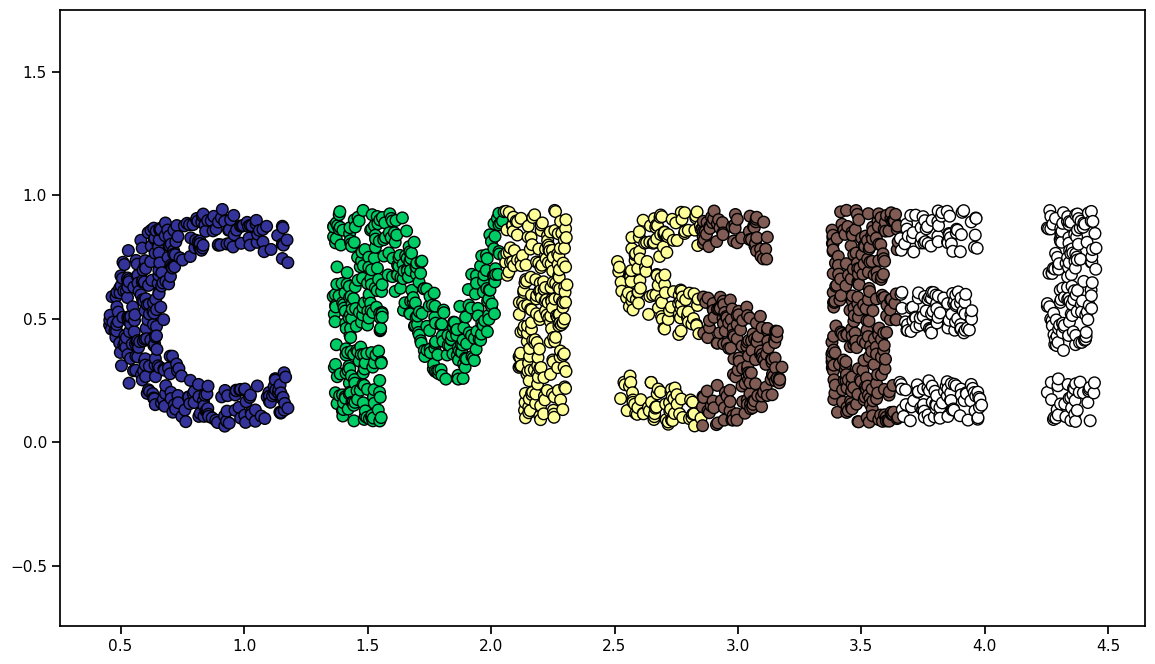
Part 2: Data Transformation#
There is a lot we can do with this dataset now. For example, let’s define some transformations of the data. I am putting transformation functions here in one place, but we will refer back to these as we go through the notebook. For now, just make a mental note of what is here and what the name of the data variable is.
Feel free to play with these now, or wait until we need them.
# rotation in 2D
def rotate(X, angle):
theta = np.deg2rad(angle)
R = [[np.cos(theta), np.sin(theta)],
[-np.sin(theta), np.cos(theta)]]
return np.dot(X, R)
X2 = rotate(X, 40) + 5
fig = plt.figure(figsize=(14,8))
plt.scatter(X2[:, 0], X2[:, 1], s=80, edgecolors='black', **colorize)
plt.axis('equal');
# rotation in 3D
def random_projection(X, dimension=3, rseed=42):
assert dimension >= X.shape[1]
rng = np.random.RandomState(rseed)
C = rng.randn(dimension, dimension)
e, V = np.linalg.eigh(np.dot(C, C.T))
return np.dot(X, V[:X.shape[1]])
X3 = random_projection(X, 3)
# X3.shape
# s curve
def make_hello_s_curve(X):
t = (X[:, 0] - 2) * 0.75 * np.pi
x = np.sin(t)
y = X[:, 1]
z = np.sign(t) * (np.cos(t) - 1)
return np.vstack((x, y, z)).T
# what does this do???
XS = make_hello_s_curve(X)
# Try plotting it.
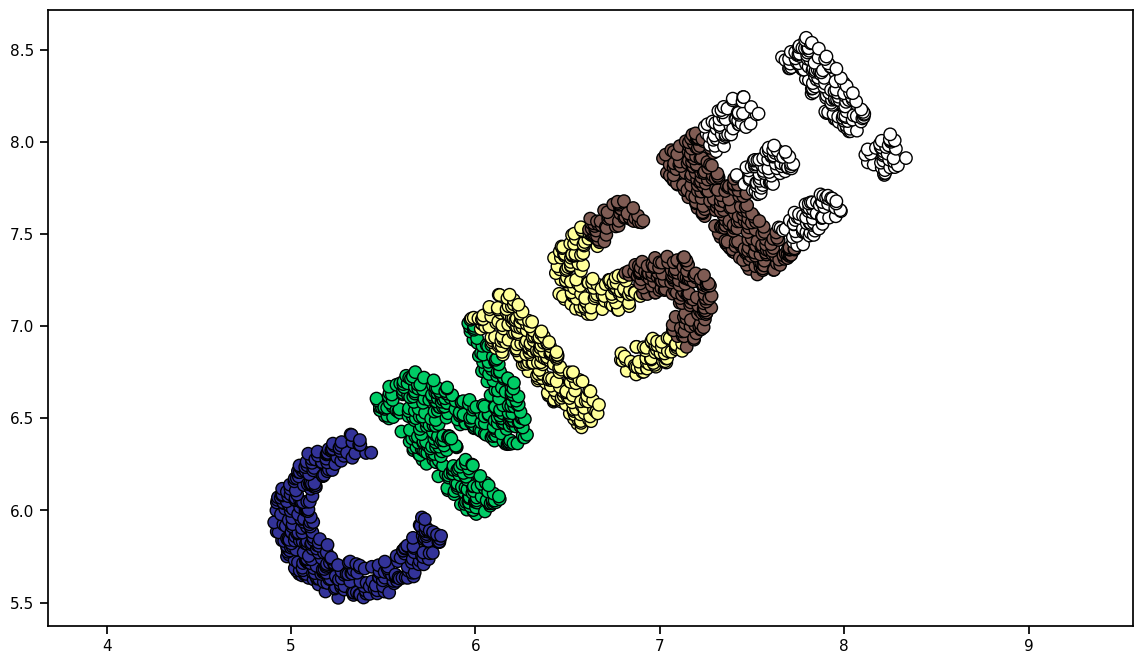
Why did we make these functions? The scaling and orientation of the data should not be important: we should find the shape of the data under any rotation or stretching. Let’s see if it works…
What is important? Typically, we think in terms of these two types:
some notion of distance (e.g., Euclidean, geodesic)
some notion of similarity.
Of course, we want to choose definitions of these types ourselves, especially in the case of similarity, because that can mean very different things in different contexts.
Let’s try similarity. Looking at the two previous datasets (unrotated and rotated), what needs to be similar? Clearly it is not the angle. However, the distances between each of the points has stayed the same. Pick a point in the C and and point in the E - those two points are still the same distance apart.
✅ Do This: Comment this code and describe in a markdown cell what the pairwise_distances library does. Comment on why we would want the algorithm to be independent of rotations. Exactly what quantities should be independent of rotations?
Read this to help.
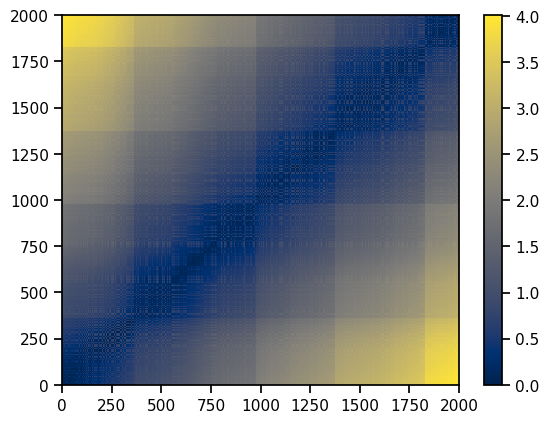
from sklearn.metrics import pairwise_distances
X_distances_eucl = pairwise_distances(X, metric='euclidean')
fig, ax = plt.subplots(1,1)
p = ax.pcolormesh(X_distances_eucl, cmap = 'cividis')
fig.colorbar(p)
<matplotlib.colorbar.Colorbar at 0x14d657e50>
Put your comments here
✅ Do This: Now, compute the distance matrix for the rotated data. Compare the distance matrix for the two datasets. Make an image, for example, of the difference between the two distance matrices and comment on your results.
You might also see if this library can help.
# Put your code here
Part 3: Multi Dimensional Scaling (MDS)#
If you wanted you could use the distance matrix you just computed - it contains all of the information that you need! (Or, you could choose another definition.) As is, however, it isn’t an obvious solution to any problem. What manifold learning attempts to do is create data using a similarity measure; in this case, we have the distances. Let’s use this information in MDS to see if it can reconstruct the data just from these “similarities”!
✅ Do This:
Comment this code. For example, how is it using the distances we explored above?
Run the code several times to see if the results change from run to run.
Time the code for different numbers of points in the dataset and make a plot of time versus number of points in the dataset.
Vary the
random_stateto see what that does.Comment on all of your results.
Warning: not much happens for this case. But, be sure to understand what is happening here before things get interesting. You will need to run it several times until you see the point.
from sklearn.manifold import MDS
from sklearn.decomposition import PCA
import time
model_eucl = MDS(n_components=2, dissimilarity='precomputed', n_jobs = -1, random_state=1)
out_eucl = model_eucl.fit_transform(X_distances_eucl)
/Users/silves28/anaconda3/envs/cmse801/lib/python3.11/site-packages/sklearn/manifold/_mds.py:298: FutureWarning: The default value of `normalized_stress` will change to `'auto'` in version 1.4. To suppress this warning, manually set the value of `normalized_stress`.
warnings.warn(
3D Projections#
Hopefully the above code built a little intuition for MDS. Let’s take that, perhaps overly simple, example to the next most simple case: 3D.
fig = plt.figure(figsize=(8,8))
ax = plt.axes(projection='3d')
ax.scatter3D(X3[:, 0], X3[:, 1], X3[:, 2], s=80, edgecolors='black', **colorize)
ax.view_init(azim=70, elev=50)
ax.set(xlabel = r"$X_1$", ylabel = r"$X_2$", zlabel = r"$X_3$")
[Text(0.5, 0, '$X_1$'), Text(0.5, 0.5, '$X_2$'), Text(0.5, 0, '$X_3$')]
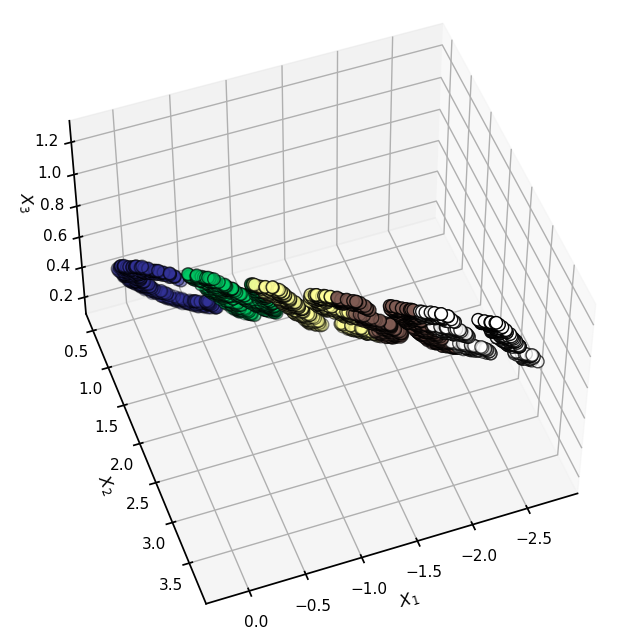
✅ Do This: Comment this code very carefully and describe what it does.
model = MDS(n_components=2, random_state=1) # note the number of components
out3 = model.fit_transform(X3) # note which data is used
fig = plt.figure(figsize=(8,8))
ax = plt.axes()
ax.scatter(out3[:, 0], out3[:, 1], s=80, edgecolors='black', **colorize)
ax.set(xlabel = r"$Z_1$", ylabel = r"$Z_2$")
ax.axis('equal')
/Users/silves28/anaconda3/envs/cmse801/lib/python3.11/site-packages/sklearn/manifold/_mds.py:298: FutureWarning: The default value of `normalized_stress` will change to `'auto'` in version 1.4. To suppress this warning, manually set the value of `normalized_stress`.
warnings.warn(
(-2.1431067764523397,
2.193472861609876,
-0.966838764906334,
1.0183857242826002)
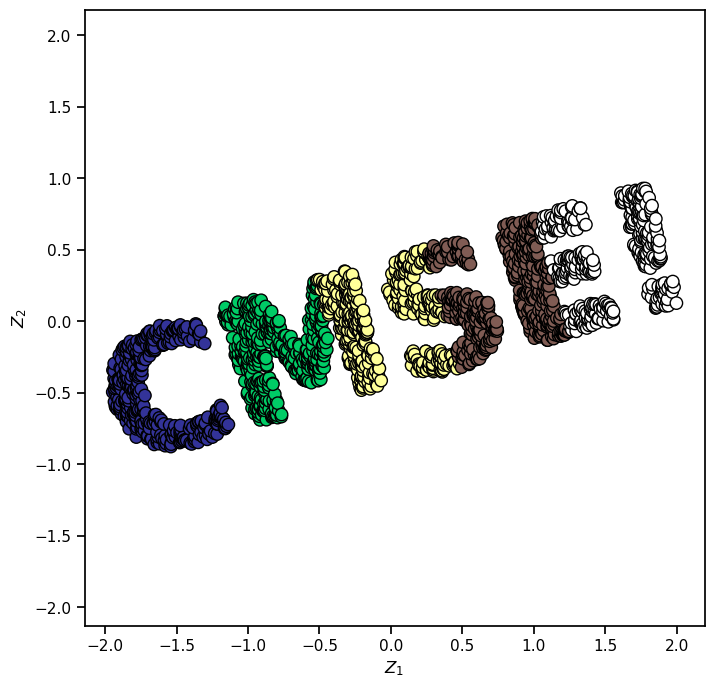
Now, the fun begins!
The data so far was subjected to linear operations: rotations in 2D and 3D. And, the similarity we used was distances. When all of the data lives in a plane, which is preserved in these transformations, we saw the distances are preserved. What happens if the transformation is nonlinear and the distances become….let’s say….more interesting?
Earlier we made a third dataset called XS - let’s take a look at it.
fig = plt.figure(figsize=(8,8))
ax = plt.axes(projection='3d')
ax.scatter3D(XS[:, 0], XS[:, 1], XS[:, 2], s=80, edgecolors='black', **colorize)
ax.set(xlabel = r"$Y_1$", ylabel = r"$Y_2$", zlabel = r"$Y_3$")
[Text(0.5, 0, '$Y_1$'), Text(0.5, 0.5, '$Y_2$'), Text(0.5, 0, '$Y_3$')]
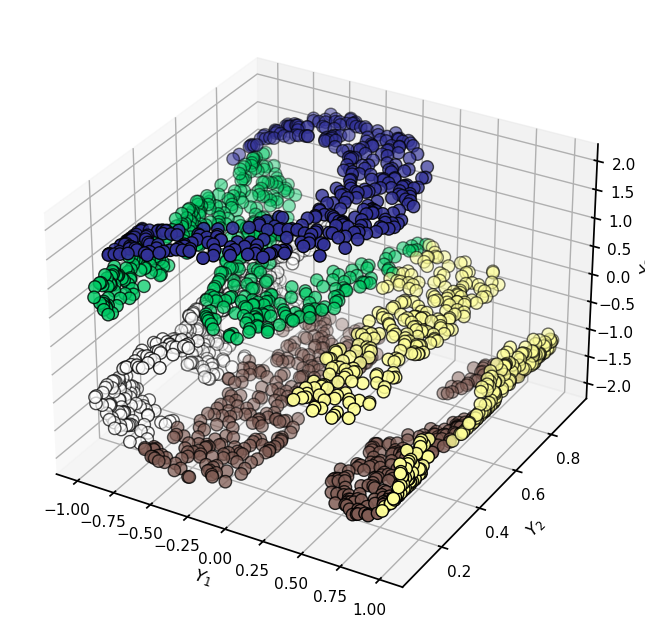
✅ Do This: Now, think about this: if we computed the distances between the points for this version of the dataset, what outcome would you expect?
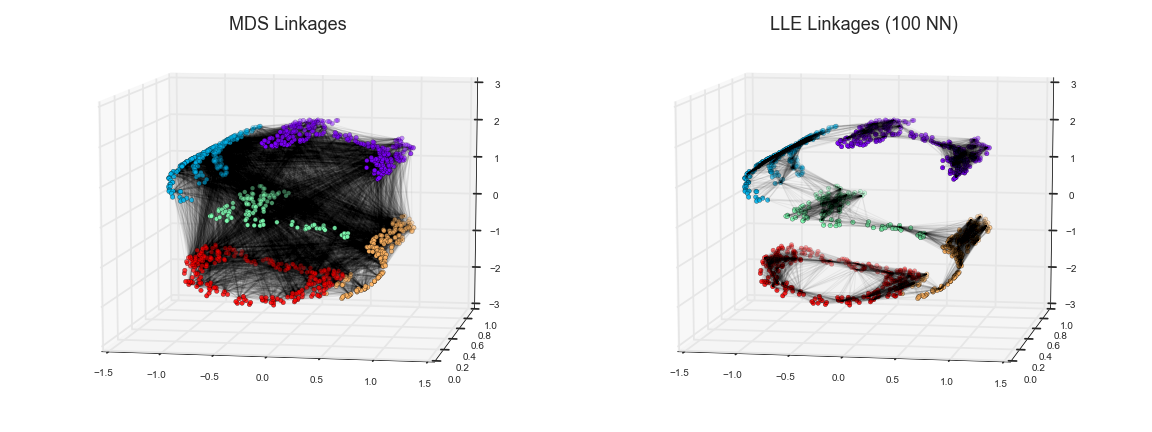
You now know how to run MDS. Take this 3D data and move it to 2D using MDS and see what you get. Explain what you see; what did MDS do? For a bit of a hint, see the image at the very top of this notebook.
What is your conclusion about MDS?
Here is some helper code to get you started:
model = MDS(????) # note the number of components
out_s = model.???? # note which data is used
fig = plt.figure(figsize=(8,8))
plt.scatter(out_s[:, 0], out_s[:, 1], s=80, edgecolors='black', **colorize)
plt.axis('equal');
Cell In[18], line 1
model = MDS(????) # note the number of components
^
SyntaxError: invalid syntax
Part 4: Locally Linear Embedding#
MDS does exactly what we tell it to do, which is to preserve the distances - all of them!
LLE takes a different approach, which is to “think globally, act locally”. We want to preserve the manifold, but we want to preserve local relationships on the manifold, just for the reasons that MDS “failed”.
✅ Do This: Run all of the data through LLE to explore how it differs from MDS. In particular, vary the number of neighbors. Also, rerun the notebook with different sequences of symbols (like your name!) to see if you see trends.
from sklearn.manifold import LocallyLinearEmbedding
model = LocallyLinearEmbedding(n_neighbors=50,
n_components=2,
method='modified',
eigen_solver='dense')
lle_out = model.fit_transform(XS)
fig, ax = plt.subplots(1,1)
ax.scatter(lle_out[:, 0], lle_out[:, 1], s=80, edgecolors='black', **colorize)
ax.set(xlabel = r"$Z_1$", ylabel = r"$Z_2$")
[Text(0.5, 0, '$Z_1$'), Text(0, 0.5, '$Z_2$')]
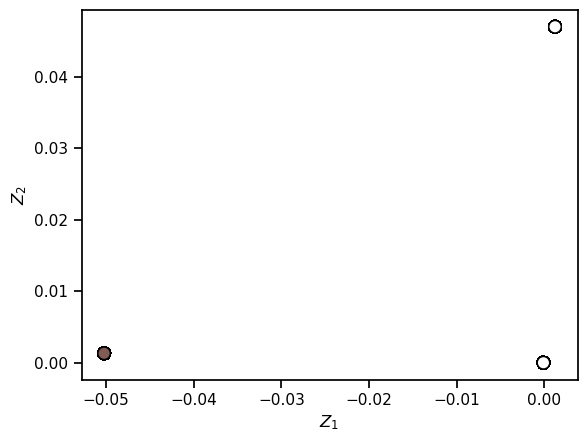
✅ Question: After using each of the datasets with different LLE hyperparameter choices, discsuss what behaviors you saw and how that compares with MDS. What are the pros and cons of each?
✎ Put your conclusions here!
© Copyright 2023, Department of Computational Mathematics, Science and Engineering at Michigan State University.