Week 04: Pre-Class Assignment:
Linear Algebra and Machine Learning#
✅ Put your name here.#
Goals for today’s pre-class assignment#
In this Pre-Class Assignment you are going to recall some linear algebra and apply it in the context of machine learning. The main learning goals are:
understand how linear algebra is used in machine learning,
perform linear regression using linear algebra,
use non-linear functions to perform linear regression.
Total number of points: 39 points
This assignment is due by 11:59 p.m. the day before class, and should be uploaded into the appropriate “Pre-Class Assignments” submission folder on D2L. Submission instructions can be found at the end of the notebook.
Part 1. Linear regression with pinv (8 points)#

In this problem you are going to implement linear regression using the pseudoinverse library in Python’s linalg. (In problem 3 below you will do this by hand, so enjoy using the pinv library while you can!)
It is highly recommended that you bookmark to the linalg documentation in Numpy, and familiarize yourself with the various options that are there.
The code below creates random pair of points \((x_i,y_i)\) and adds a little bit of noise to them.
✅ Task 1.1: (2 points) Create the data matrix \({\bf X}\) called X_data.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# This creates fake data for us to use.
x = np.linspace(0,10, 10)
y = - x/2 + np.random.randn(x.shape[0])
# Create the data matrix
X = np.ones( (x.shape[0],2))
X[:,1] = x
✅ Task 1.2: (4 points) Calculate the pseudo-inverse of X_data and use it to calculate the slope and intercept of the regression line.
p_inv = np.linalg.pinv(X) # 1 point for calling pinv
slope = np.matmul(p_inv,y)[1] # 2 point (product + indexing)
inter = np.matmul(p_inv,y)[0] # 2 point (product + indexing)
plt.plot(x, y, '^', label = 'Original Data')
plt.plot(x, slope*x + inter, label = 'Fit line')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
✅ Task 1.3: (2 points) Create new fake data (with noise or without noise) using a different equation and recalculate the fit to show that your code works for more than the one simple case. This is a good time to play with your code by trying lots of csaes that will build your intuition.
# This creates fake data for us to use.
x = np.linspace(0,10, 10)
y = 2 * x + 5 + np.random.randn(x.shape[0])
p_inv = np.linalg.pinv(X) # 1 point for calling pinv
slope = np.matmul(p_inv,y)[1] # 2 point (product + indexing)
inter = np.matmul(p_inv,y)[0] # 2 point (product + indexing)
plt.plot(x, y, '^', label = 'Original Data')
plt.plot(x, slope*x + inter, label = 'Fit line')
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
Part 2. Radial Basis Functions (19 points)#
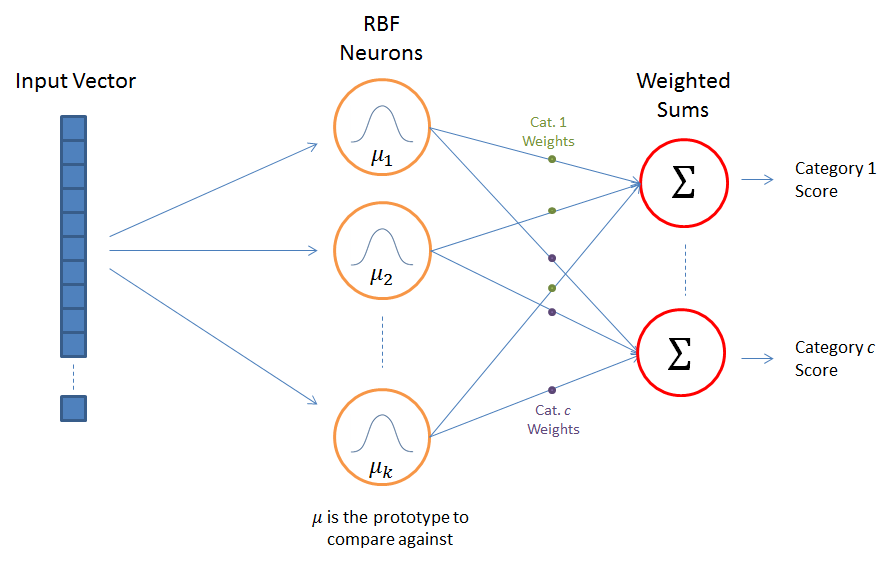
When we first encounter linear regression it might be in the context of fitting a line of the form \(mx+b\) to some data; or, more generally, \({\bf w}^T{\bf x}\) in higher dimensions. This structure occurs very widely in machine learning contexts because linear operations are much easier to handle and because we might want to linearly combine inputs before performing a nonlinear operation \(\sigma\), as in \(\sigma({\bf w}^T{\bf x}\) .
As discussed in the lecture, it would be extremely powerful if there were a way to include non-linearities while still exploiting everything we know (e.g., fast Python libraries) about linear algebra.
One way to do that is to linearly combine non-linear functions, as in
where in this case all of the \(K\) are the same functions, but they are located at the “centers” \({\bf x}_c\). Note that the \(K\) act as a basis function and that they only depend on the radial distance \(|{\bf x} - {\bf x}_c|\); hence, they are called “radial basis functions” or RBFs for short. The RBFs are generally nonlinear functions, such as Gaussians, which we will use here.
The machine learning idea behind RBFs is rather simple: we wish to take some data, in the form of \(\{{\bf x}_i\}\) and \(\{f({\bf x}_i)\}\), to inform what we think \(f({\bf x})\) looks like at any \({\bf x}\) and make predictions based on that; this is a standard ML regression problem. The reason this is a linear problem is that once we have the data we can form the numbers \(K(|{\bf x}_i - {\bf x}_c|)\); then, solving for the \(\alpha_c\) is a linear algebra problem:
Or, just:
✅ Task 2.1: (2 points) Compute and plot \(x \cos(x)\) on an interval \(x\in [0, 2\pi]\); this is your “actual” function.
def func(x):
return x * np.cos(x)
x = np.linspace(0., 2.0 * np.pi, 100)
y = func(x)
plt.plot(x,y)
plt.xlabel('x')
plt.ylabel('y')
✅ Task 2.2: (2 points) Form your data \(f\) from the function above at the points \(x\in [1, 2, 3, 4]\) - this your fake data.
x_data = np.array([1, 2, 3, 4])
f = func( x_data)
✅ Task 2.3: (4 points) Assume that the \(K\)s are Gaussians \(\exp(-x^2)\) and compute the matrix \({\bf K}\).
def kernel(x, c):
return np.exp(-(x - c)**2)
K = np.zeros( (len(x_data), len(x_data)) )
for i,xi in enumerate(x_data):
for j, xj in enumerate(x_data):
K[i,j] = kernel(xi, xj)
✅ Task 2.4: (2 points) Using SciPy’s linalg.solve package, solve for the coefficients \(\alpha_c\).
alphas = np.linalg.solve(K,f)
✅ Task 2.5: (2 points) Plot your function \(f\) by summing for the Gaussians weighted by the \(\alpha_c\), in the same plot as the data points, as well as each term in the sum of Gaussians as a dashed line.
f_reg = np.zeros( len(x))
for i, xi in enumerate(x_data):
f_reg += alphas[i] * kernel(x, xi)
# Actual function
plt.plot(x, y, label = "Actual Function")
# Data points as red dots
plt.plot(x_data, f, 'ro', label = "Regression Points")
# RBF model
plt.plot(x, f_reg, ls = '--', label = "RBF Model")
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
✅ Task 2.6: (5 points) Next, you are going to explore what would have happened if you have less data. Follow these steps:
Copy the code from above in a new code cell below.
Change the names of the variables so that nothing gets overwritten.
Remove both the interior points (\(x = 2, 3\)) from the data.
Rerun the code to get a new prediction with only half the data.
Plot the actual function, the prediction with four points and the prediction with two points.
# Remove two data points
x_data_2 = np.array([1, 4])
f_2 = func(x_data_2)
# Reconstruct the K matrix
K_2 = np.zeros( (len(x_data_2), len(x_data_2)) )
for i,xi in enumerate(x_data_2):
for j, xj in enumerate(x_data_2):
K_2[i,j] = kernel(xi, xj)
# Calculate the alphas
alphas_2 = np.linalg.solve(K_2,f_2)
# Recalculate the RBF model
f_rbf_2 = np.zeros( len(x))
for i, xi in enumerate(x_data_2):
f_rbf_2 += alphas_2[i] * kernel(x, xi)
# Actual function
plt.plot(x, y, label = "Actual Function")
# Data points as red dots
plt.plot(x_data, f, 'ro', label = "Regression Points")
# RBF model with 4 points
plt.plot(x, f_reg, ls = '--', label = "RBF Model 4 points")
# RBF model with 2 points
plt.plot(x, f_rbf_2, ls = '--', label = "RBF Model 2 points")
plt.legend()
plt.xlabel('x')
plt.ylabel('y')
✅ Task 2.7: (2 points) In the text/markdown cell below, write your conclusions. In particular, think about having done this in reverse where you started with two points, holding two back, and then compared with the full data set to see if your prediction changed. Also, what does this tell you about ML situations where the data is too sparse?
✎ Put your answers here!
Part 3. Normal Equation by Hand (12 points)#
In this problem you are going to get more practice using the pseudoinverse, this time by hand to get practice with simple matrix operations by hand. There are two parts to this problem: one for which the pseudoinverse is, in fact, not needed and one for which it is needed. The former part is to build your intutition and to show that the method reduces to a well-known result. The latter is to use some libraries on a more complex problem. You will also get some practice using \(\LaTeX\) for linear algebra problems.
You are given some data in the form \({\bf x} = [0, 1]\) and \({\bf y} = [0, 2]\) - quite a huge dataset! Your hypothesis is a linear model and you wish to find the weights. Once you know the weights you can predict values of \(y\) for new choices of \(x\). The hypothesis takes the form
Obviously for this case you can easily solve this problem as was shown in class; but, here you will use the pseudoinverse. To get you started, the matrix equation to be solved is:
Note how \(w_0\) is used as a “bias” or “intercept” here, which gives the entry \(1\) in the \(X\) matrix. Recall that each row is a member of the dataset, which is why there are two rows (but, see part 3B of this problem…).
✅ Task 3.1: (8 points) In the next markdown cell, use \(\LaTeX\) to write down these quantities, working out each quantity by hand (no code, just \(\LaTeX\), until the final step):
the matrix \(X\) for this dataset
the vector \({\bf y}\) for this dataset
the transpose \(X^T\)
the product \(X^TX\)
the inverse \((X^TX)^{-1}\)
the product \((X^TX)^{-1}X^T\)
the product \((X^TX)^{-1}X^T{\bf y}\)
the vector \({\bf w}\)
the matrix \(X\) for this dataset: $\( X = \begin{pmatrix} 1 & 0 \\ 1 & 1\end{pmatrix} \)$
the vector \({\bf y}\) for this dataset: $\( {\bf y} = \begin{pmatrix} 0 \\ 2 \end{pmatrix} \)$
the transpose \(X^T\): $\( X^T = \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix} \)$
the product \(X^TX\): $\( X^TX = \begin{pmatrix} 2 & 1 \\ 1 & 1 \end{pmatrix} \)$
the inverse \((X^TX)^{-1}\): $\( (X^TX)^{-1} = \begin{pmatrix} 1 & -1 \\ -1 & 2 \end{pmatrix} \)$
the product \((X^TX)^{-1}X^T\) $\( (X^TX)^{-1}X^T = \begin{pmatrix} 1 & 0 \\ -1 & 1 \end{pmatrix} \)$
the product \((X^TX)^{-1}X^T{\bf y}\) $\( (X^TX)^{-1}X^T {\bf y} = \begin{pmatrix} 0 \\ 2 \end{pmatrix} \)$
the vector \({\bf w}\) $\( {\bf w} = \begin{pmatrix} 0 \\ 2 \end{pmatrix} \)$
✅ Task 3.2: (2 points) Put all the above into code and plot the data points and the line obtained from the weights \(\bf w\).
x = np.array([0, 1])
y = np.array([0, 2])
X = np.array([[1, 0],
[1, 1]]
)
# Calculate w
X_T = np.transpose(X)
print("X_T X = \n",X_T@ X)
Xinv= np.linalg.inv(X_T@X)
print("\ninv(X_T X) = \n", Xinv)
xxx = Xinv @ X_T
print("\ninv(X_T X) X_T = \n", xxx)
w = xxx @ y
print("\nw = inv(X_T X) X_T y = \n", w)
plt.plot(x, y, '^')
x_fine = np.linspace(0,1.1)
plt.plot(x_fine, w[0] + w[1]*x_fine)
plt.xlabel('x')
plt.ylabel('y')
plt.grid(alpha = 0.15)
✅ Task 3.3: (2 points) Repeat what you just did but using the new dataset \({\bf x} = [0, 1, 2]\) and \({\bf y} = [0, 2, 3]\), this time using code. Do not use the pinv library this time! Show your result in a plot.
Some helper code is given here:
x = np.array([0, 1, 2])
y = np.array([0, 2, 3])
X = np.array([[1, 0],
[1, 1],
[1, 2]]
)
X_T = np.transpose(X)
print("X_T X = \n",X_T@ X)
Xinv= np.linalg.inv(X_T@X)
print("\ninv(X_T X) = \n", Xinv)
xxx = Xinv @ X_T
print("\ninv(X_T X) X_T = \n", xxx)
w = xxx @ y
print("\nw = inv(X_T X) X_T y = \n", w)
plt.plot(x, y, '^')
x_fine = np.linspace(0.0,2.1)
plt.plot(x_fine, w[0] + w[1]*x_fine)
plt.xlabel('x')
plt.ylabel('y')
plt.grid(alpha = 0.15)
Assignment wrap-up#
Please fill out the form that appears when you run the code below. You must completely fill this out in order to receive credit for the assignment!
from IPython.display import HTML
HTML(
"""
<iframe
src="https://forms.office.com/r/QyrbnptkyA"
width="800px"
height="600px"
frameborder="0"
marginheight="0"
marginwidth="0">
Loading...
</iframe>
"""
)
© Copyright 2023, Department of Computational Mathematics, Science and Engineering at Michigan State University.