Week 04: In Class Assignment:
Singular Value Decomposition (SVD) and Principal Component Analysis (PCA)#
✅ Put your name here.#
✅ Put your group member names here.
Unsupervised Learning#
The goals of unsupervised learning are very different from supervised and reinforcement learning. One goal is called “dimensionality reduction”. We will spend an entire week on this when we get to Chapter 8; today we will focus on the underlying linear algebra that is behind some of those methods. The goal is that you have a bit more insight once we get to that part of the course! So, let’s get to some linear algebra!
Part 1. Matrix Decompositions#
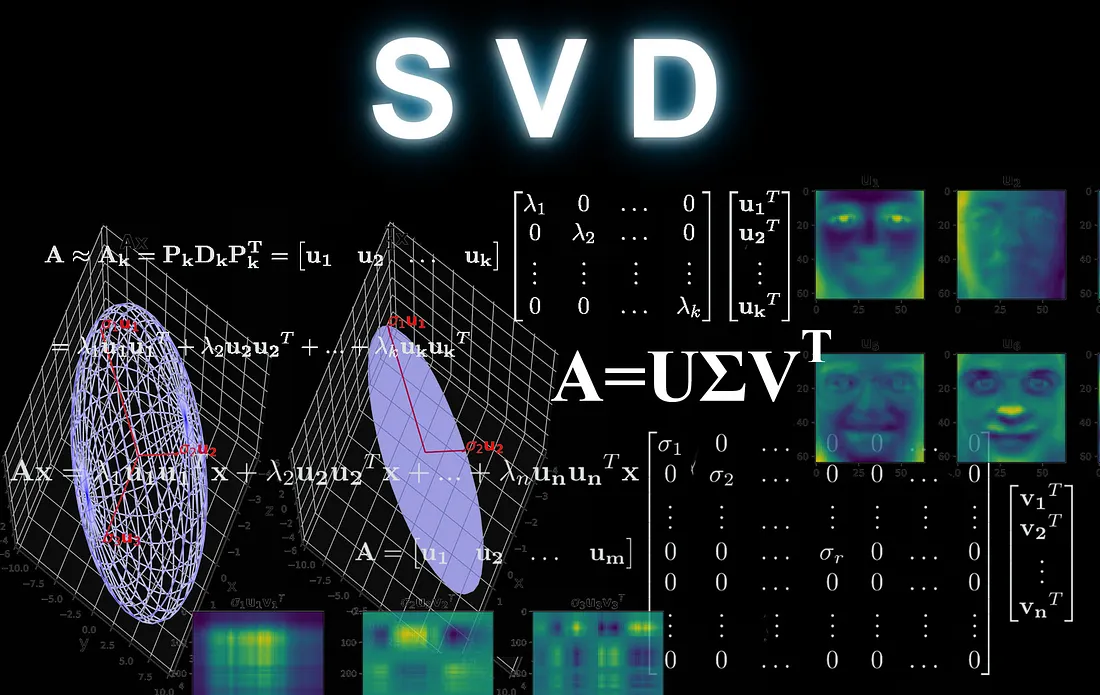
In the lecture it was mentioned that it is often benefical to write matrices in terms of products of matrices that have selected properties. These had names like eigendecomposition, Cholesky, QR and so on. Today you will become expert on one called SVD, which stands for “Singular Value Decomposition”. If by any chance you have worked with the eigendecomposition before, this is the generalization to rectangular matrices; if not, don’t worry about it.
In the SVD decomposition some data matrix \({\bf X}\) is written as $\({\bf X} = {\bf U}{\bf \Sigma}{\bf V}^T,\)$ where
\({\bf U}\) is a square, unitary matrix,
\({\bf \Sigma}\) is a rectangular, diagonal matrix,
\({\bf V}\) is a square, unitary matrix.
This probably seems like a very odd thing to do! Before we get to why this might be interesting and useful, let’s be sure we know what all of this means. Answer these questions and discuss them within your group:
✅ Task: Answer the following questions:
What is a “unitary matrix” and what are some of its properties?
What is a “diagonal matrix” and what are some of its properties?
What is the name given to the values in the matrix \({\bf \Sigma}\)?
If the data matrix \({\bf X}\) has a shape \(m\times n\), what are the shapes of the other three matrices?
✎ Put your answers here!
…
…
1.2 Properties of the SVD#
As we just saw, the matrix \({\bf \Sigma}\) is diagonal. Let’s suppose that we choose to write it as
The SVD the values \(\sigma_1, \sigma_2, \ldots\) are called the “singular values”, which is where SVD gets its name.
Hint: If you are not an expert at markdown and \(\LaTeX\) yet and you see something in a notebook you want to use, click in the markdown cell to see how it was coded; for example, if you want to put a matrix into this notebook, you can copy the \(\LaTeX\) from the cell above. This can save time figuring out \(\LaTeX\) commands you don’t know yet.
✅ Task: Answer the following questions:
If the data array \({\bf X}\) has dimensions \(m\times n\), how many singular values are there?
What happens when you multiply a matrix with a diagonal matrix? We want to break down the SVD: what form does \({\bf \Sigma}{\bf V}^T\) generally have? Give an explicit example using \(\LaTeX\) for a \(2\times 2\) \({\bf X}\). (In general \({\bf X}\) will not be square, of course, but use something as simple as you can to illustrate your result.) Feel free to use the whiteboards to work this out with your group.
Let’s suppose that we (everyone on Earth) agrees that when we perform an SVD that we always order the singular values in order from largest to smallest, \(\sigma_1 > \sigma_2 > \sigma_3 \ldots\). Let us further suppose that many of the singular values are quite small, negligible compared to the first few, allowing us to simply set them to zero. Work out and demonstrate using \(\LaTeX\) what the consequences are. That is, what form does \({\bf \Sigma}{\bf V}^T\) have when \({\bf \Sigma}\) is both diagonal and has many zeros along the lower-right portion of the diagonal.
What about the overall form \( {\bf U}{\bf \Sigma}{\bf V}^T\)? Think about what we talked about in the first lecture about dimensionality reduction: even if it is vague and still a bit abstract, describe how setting the smallest singular values to zero roughly contains the notion of reducing the dimensionality of the problem. It might help to sketch out the shapes of the matrices on the chalkboards with your group using arbitrary matrices with elements \(M_{ij}\). (Hint: you might work out the entire SVD for a \(3\times 3\) where there is only one retained singular value \(\sigma_1\).) Compare the full data matrix \({\bf X}\) with the one you get when you see most of the singular values to zero.
✎ Put your answers here!
…
…
1.3 Let’s code.#
✅ Task: You won’t be surprised to learn that SVD is built directly into SciPy’s linalg library. Look up, using the internet, how to use the svd library and complete the code below, adding comments to the most important lines and answering the questions in the comments.
Notice that there are several lines commented out. Think of the matrix that is being made as the data in 2D. Try all of the lines, one at a time, and understand what structure the data has by looking at the plots. For each case, discuss in the markdown cell below what \({\bf \Sigma}\) is telling you about the structure of the data.
from scipy import linalg
import numpy as np
import matplotlib.pyplot as plt
# Try each of these to see what different data "shapes" have on the SVD.
### What pattern do you see in S as the data takes different "shapes"?
x = np.array([[0, 0.5], [0.0, -0.5]])
# x = np.array([[0.5, 0.0], [-0.5, -0.0]])
# x = np.array([[-0.5, -0.5], [0.5, 0.5]])
# x = np.array([[-0.5, 0.2], [0.5, -0.2], [0.0, 0.3]])
# x = np.random.randn(50, 2)
### What does this do!? Are there other options?
U, S, V_T = ...
print('The SVD is:')
print('\n U = ', U)
print('\n S = ', S)
print( '\n V_T = ', V_T, '\n')
plt.scatter(x[:,0], x[:,1])
### ANSWER
from scipy import linalg
import numpy as np
import matplotlib.pyplot as plt
# Try each of these to see what different data "shapes" have on the SVD.
### What pattern do you see in S as the data takes different "shapes"?
x = np.array([[0, 0.5], [0.0, -0.5]])
# x = np.array([[0.5, 0.0], [-0.5, -0.0]])
# x = np.array([[-0.5, -0.5], [0.5, 0.5]])
# x = np.array([[-0.5, 0.2], [0.5, -0.2], [0.0, 0.3]])
# x = np.random.randn(50, 2)
### What does this do!? Are there other options?
U, S, V_T = linalg.svd(x, full_matrices = True)
print('The SVD is:')
print('\n U = ', U)
print('\n S = ', S)
print( '\n V_T = ', V_T, '\n')
plt.scatter(x[:,0], x[:,1])
✎ Put your answers here!
…
…
1.4 Image compression#

Let’s now apply SVD to image compression. The code below loads an image, makes a black and white version of it, and plots both versions. The title of each plot shows the size of the data. Note how the color image has three dimensions, that is because there are three color channels: R, G ,B. SVD works on matrices so we need to reduce the dimensionality by taking the mean of three channels and make the black and white version of the colored image.
from matplotlib.image import imread
color_img = imread("Beaumont_Tower_South_Side.jpg") # Choose an image of your choice.
# Make a black and white version
bnw_img = np.mean(color_img, -1)
fig, ax = plt.subplots(1, 2, figsize = (12, 7))
img = ax[0].imshow(color_img) # Note how imshow knows that there are three color channels
img = ax[1].imshow(bnw_img)
img.set_cmap('gray')
ax[0].set_title(f'Size = {np.shape(color_img)}')
ax[1].set_title(f'Size = {np.shape(bnw_img)}')
for a in ax:
a.axis('off')
# Extra code for showing each color channel
# Make a plot for each color channel
# fig, ax = plt.subplots(1,3, figsize= (16, 6))
# img = ax[0].imshow(color_img[:,:,0])
# img.set_cmap('Reds')
# img = ax[1].imshow(color_img[:,:,1])
# img.set_cmap('Greens')
# img = ax[2].imshow(color_img[:,:,2])
# img.set_cmap('Blues')
# for a in ax:
# a.axis('off')
✅ Task: Your task is to use SVD to make three (or more) images by keeping only a subset of the singular values. The code below makes a 2x2 grid where you can put your plots. You need only calculate the SVD of the black and white image, reconstruct the image, and plot it using imshow. You also need to calculate the reduction in size that you would get if you were to store only the reduced SVD matrices instead of the whole original matrix.
U, sigmas, VT = np.linalg.svd(bnw_img)
S = np.diag(sigmas)
fig, axes = plt.subplots(2,2, figsize = (16, 16))
ax = axes.flatten()
for i, r in enumerate([4, 40, 400]):
# Construct approximate image
Xapprox = U[:,:r] @ S[0:r,:r] @ VT[:r,:]
ratio = (U[:,:r].size + S[0:r,:r].size + VT[:r,:].size)/bnw_img.size
img = ax[i].imshow(Xapprox)
img.set_cmap('gray')
ax[i].axis('off')
ax[i].set_title(f"Rank = {r}, Storage = {ratio*100:.2f}%" )
img = ax[3].imshow(bnw_img)
img.set_cmap('gray')
ax[3].axis('off')
ax[3].set_title(f"Original size {np.shape(bnw_img)}" )
Part 2. Principal Component Analysis#
As mentioned above we will use the tricks of linear algebra later in the course to perform dimensionality reduction, especially in Chapter 8. One ML algorithm we will encounter there is principal component analysis (PCA), which is very commonly used to reduce the dimensionality of a dataset either to visualize it or to prepare the data before it enters into another ML algorithm. Since we just built our intuition on lowering the dimensionality with SVD and we already know how to grab datasets and use sklearn, let’s see what PCA does. Later we will make the connections between SVD and PCA stronger; the connection might still be slightly abstract at this point, but we will get there soon!
First, let’s grab a dataset - the iris dataset. The iris dataset is four dimensional, making it impossible to directly visualize except through a very awkward approach (something like the Seaborn pairplot). Let’s see if PCA can help!
Look through this code and discuss anything you don’t understand with your group.
from sklearn.datasets import load_wine
import pandas as pd
from sklearn.decomposition import PCA
import seaborn as sns
data = load_wine()
wine = pd.DataFrame(data.data, columns=data.feature_names)
wine['class'] = data.target
wine.head()
Preprocessing Data Before ML#
One of the important steps in ML is scaling the data. This is extremely important in ML because you can make one of the features totally swamp the other features simply by mulitplying its values by a large number (which could happen if, for example, you switched to different units, such as nanometers). Not surprising, this is so standard in ML that it is built into sklearn and is even called “standard”:
missing_values = wine.isnull().sum()
print(missing_values)
# Extract numerical features
X = wine.drop(columns=['class'])
# Standardize the data
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
✅ Task: What did StandardScaler do to the data? Write down the math in the cell below
Discuss the code below and its output within your group. Open a new markdown cell below and answer the questions.
# Q1. What does this do?
pca = PCA(n_components=2)
# Q2. What does this do? What must the structure of x be?
principalComponents = pca.fit_transform(X_scaled)
# Note that a lot of the code is simply managing/visualizing the data, not
# doing the ML!
principalDf = pd.DataFrame(data=principalComponents, columns=['PC1', 'PC2'])
finalDf = pd.concat([principalDf, wine[['class']]], axis=1)
plt.figure(figsize=(8,6))
classes = list(data.target_names)
colors = ['c', 'm', 'y']
for cls, color in zip(classes, colors):
indicesToKeep = finalDf['class'] == classes.index(cls)
plt.scatter(finalDf.loc[indicesToKeep, 'PC1'], finalDf.loc[indicesToKeep, 'PC2'], c=color, s=50)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('2 component PCA for Wine Dataset')
plt.legend(classes)
plt.grid()
plt.show()
✅ Task: In the code cell below answer the following questions:
What does
pca = PCA(n_components=2)do ?What does
principalComponents = pca.fit_transform(X_scaled)do? What must the structure ofxbe?What are your thoughts on what PCA is doing? Does your group feel that PCA might be a good way to visualize high-dimensional data? Can you think of a better way?
How does your plot change if you didn’t scale the data?
If you are familiar with PCA, how are PCA and SVD related?
✎ Put your answers here!
Congratulations, you’re done!#
Submit this assignment by uploading it to the course Desire2Learn web page. Go to the “In-class assignments” folder, find the appropriate submission link, and upload it there.
%%html
<marquee style='width: 40%; color: green;'><b>Congrats, you are done!</b></marquee>
© Copyright 2023, Department of Computational Mathematics, Science and Engineering at Michigan State University.