Week 10: Pre-Class Assignment: Clustering#
✅ Put your name here.#

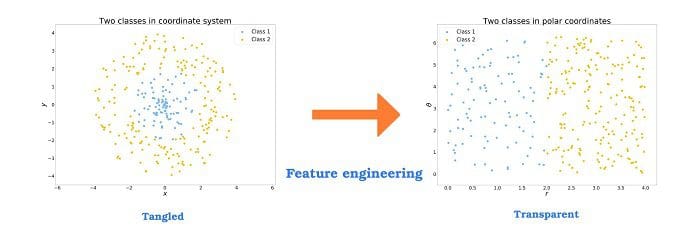
Goals of this assignment#
There are three logical parts to this HW and two due dates. The parts are:
feature creation and selection: there were many great questions about this, so let’s each work through a simple example,
clustering, since that is the subject of this week,
Total number of points: 54 points
This assignment is due by 11:59 p.m. the day before class, and should be uploaded into the appropriate “Pre-Class Assignments” submission folder on D2L. Submission instructions can be found at the end of the notebook.
Part 0: Reading#
Read chapter 9 of your textbook. Read through questions 1 - 13 at the end of the chapter
If you have any questions about anything in that chapter please contact me. Or, if you found anything particularly interesting, let me know that as well!
Part 1: More and More Features (28 points)#
In this next portion of the PCA, we will explore two key ideas in Machine Learning that are not necessarily related to this week’s topic of clustering. But, these three ideas are central to any ML workflow.
These two topics are:
feature engineering: creating more new features that help the ML find patterns,
feature ranking: determining which features have the most impact.
Next week, we will examine the opposite:
dimensionality reduction of features: find new, but fewer, features.
As we will see, these three ideas are closely related and can be used together or even viewed as opposing ideas (creating more features versus dropping features).
We’ll use a somewhat boring example of linear regression in 1D so that everything is easy to understand and visualize, but the ideas are very general and obviously much more interesting for more complex data.
Let’s make some fake data first.
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['axes.spines.right'] = False
mpl.rcParams['axes.spines.top'] = False
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
# Let's display them
def complicated_unknown_model(x,a,b, c):
return a * np.cos(x) + b *np.sin(-x) + c*np.random.randn( len(x))
num_points = 10
x = np.linspace(0, 1.5*np.pi, num_points)
a, b, ns = 1.2, -0.3, 0.6
y = complicated_unknown_model(x, a,b,ns)
fig, ax = plt.subplots(1,1, figsize =(8,6) )
ax.plot(x, y, 'o', markersize=12, label = 'Noise Data')
ax.grid(alpha=0.2)
_ = ax.set( xlabel ="x", ylabel ="y")
Next, we are going to put this through linear regression.
Make sure you understand these steps. Add comments to the code if you need.
X = x.reshape(-1,1)
lin_reg_obj = LinearRegression().fit(X,y)
lin_reg_obj.score(X,y)
As you can see, the score isn’t all that great. Let’s plot the prediction to see what the issue is.
✅ Task: (4 points) Get the coefficients and plot the prediction of the linear model together with the data.
# the data with my linear prediction
Part 1.2: Polynomial Features (15 points)#
Maybe if we had more features, this would work better?
✅ Task: (2 points) Next, read this and extend your intial dataset to include features up to \(X^3\) and finally print the new transformed dataset.
This preprocessing step is just one way to make more features; you wouldn’t always want to use a polynomial approach, but it is very often a great start if you have nothing else to guide you. You may want to do this for your project, so be sure you know what is happening here.
# Put your code here
✅ Questions: (1 point) What do the rows and columns of your new dataset correspond to?
Put your answer here
✅ Task: (2 points) Perform the linear regression again with your expanded dataset and check the new score using the increased number of features.
# Put your code here
Did your score improve? Do you think we should stop here and be done? Of course not.
✅ Task: (6 points) Re-run your linear model by adding features for polynomials up to order 10 (step by 1). The make two plots: one showing the original data with the prediction of each model and one showing the score versus the order of the polynomial. Don’t forget plot axis labels, and legends
What we have done is create a higher-dimensional feature space. Because we have more features, it is harder to plot our prediction in terms of those features. But, this is not what we want to do anyway. We want use these features as terms in a polynomial and make a plot just like we did to start with!!
✅ Task: (4 points) With this working, loop over different noise levels and polynomial orders and calculate the score for each. Then make two plots: one showing the score vs the polynomial order at different noise levels and one plot showing the scores vs the noise level at different polynomial orders. Don’t forget the axis’ labels and plot legends Be creative with the visualization
orders = [3, 5, 7, 9]
noise = [ 0.05, 0.2, 0.5, 0.8]
scores = np.zeros( (len(noise), len(orders)) )
fig, ax = plt.subplots(1,2,figsize = (10,6))
Ok, at this point you know how to systematically create more, new features using the ones you were given. You don’t need to make polynomial features, of course, and your insight into your application might suggest something else.
I’ll give you an example from experience. I was once creating lots of features and found that certain curves were very challenging to model even with many polynomial features. Shouldn’t very high polynomials always work? Even if they work in principle, there may be cases where they are extremely inefficient. Imagine if the data were created from $\(f(x) = \frac{A}{1 + x^B}.\)$ This is hard to model with an polynomial; but, we now know how to use this information as a new input feature!
And, you should note that this is not limited to regression: you could also do this with classification. Again, see the pictures at the top of this notebook.
You should have noticed that the .score tends to improve as you add more features, but with the risk of overfitting. Quick caveat on overfitting…
Regularization Caveat#
To keep this PCA not too long, we will not do the obvious, which is to explore regularization to control overfitting. But, we did this last week so you could try and explore that here
We have seen that making more features is better. You might recall this really helped when we played with the neural network playground. But, we have no way (yet) to know which features are best or if we even need all of them - maybe we are creating more than we need?
Part 1.3: Recursive Feature Elimination (RFE) (13 points)#
Next, consider these two scenarios:
you don’t have many features, and they aren’t working well; you do something like the above to create a lot of new features, but you want to get rid of those new features that are not helping and/or you are interested in which were the most useful,
you have a dataset with a lot of features, perhaps hundreds, and they are really slowing down your ML
.fits, your hyperparameter tuning and so on - you would like to know which of your hundreds of features are doing most of the work so that you can get rid of the rest and not melt your laptop.
These situations are so common in ML that there are sklearn libraries to help you. Go to this webpage and see what is there. In particular, read about VarianceThreshold - this is intuitive and easy to use. Here, however, we will examine RFE. Read its webpage to get familiar with it.
RFE is an interesting library: to use it, you pass it the estimator. This is because RFE will run your ML many times for you with different features as it tries to figure out which ones matter. As you can imagine, this can take a while for large datasets.
Let’s try it….
✅ Task: (4 points) Run the RFE with the LinearRegression model using the transformed dataset with polynomial features of order 10. Then print out the ranking.
from sklearn.feature_selection import RFE
# Put your code here
✅ Questions: (5 point)
Which feature is the most important? What power does it correspond to?
Vary the arguments in the function calls in this code until you understand how to use it. Then, open a markdown and answer these questions:
what does
ranking_give you?what does
n_features_to_selectdo?what is
stepfor and what if you change it?which feature tends to always be the least useful, and why?
Be sure to try this with many polynomials of varying order so that you don’t convince yourself of something that is only true for one case. And, feel free to change the properties of the fake data - since you have all of this coded in front of you, might as well play with it.
Put your answers here
✅ Task: (4 points) Your final step. Take all of the code you have above and check to see if RFE is doing what you think. That is, take the output of RFE and drop different features (columns of your updated dataset) and check that RFE is giving you good information.
# Put your code here
Part 2: Examining Clustering Algorithms (with labeled data - shhh!!) (26 points)#
What you will do in this portion of the assignment is answer this question: which clustering method that was discussed in the lecture is best at figuring out how many species of penguins there are in a dataset.
That is, do physical measurements of penguins cluster in way that we can spot the number of different species, if we didn’t know it already?
That is, if we only use:
bill_length_mm
bill_depth_mm
flipper_length_mm
body_mass_g_,
can we figure out how many penguin species there are?
We will use the penguin dataset we have used before. Recall that we used this for classification, so we know the answer - we just won’t use it other than to see how well clustering works on its own without the labels.
What you will do:
pick 2 clustering algorithms: we discussed four in class (DBSCAN, KMeans)
you will score these in two ways: visual inspection (since we actually do have labels) and using the silouette score
perform the clustering in 2D and 4D:
2D: pick two of the columns and treat that as 2D – this allows you to make scatter plots, and you can compare the predicted clusters with a plot colored by the known answer
4D: here, you can’t easily visualize the clusters, but you can examine the silhouette score and compare it to what you got in 2D.
From a feature engineering perspective, which columns tend to be best at finding the number of clusters/species? For example, if you do this in 2D and get silhouette scores, which two columns get closest to predicting that there are three clusters? What if you use three columns? Four? You can see how the feature engineering done above is connected to unsupervised clustering.
import seaborn as sns
penguin_df = sns.load_dataset("penguins").dropna()
penguin_df
By doing some EDA first, you can see how much clustering there is. Of course, for this HW, we are cheating because we can add color labels by species.
# sns.pairplot(penguin_df, hue="island")
sns.pairplot(penguin_df, hue="species")
Now, let’s do EDA from an unsupervised perspective by removing the hues. This will reveal to us the difference between supervised and unsupervised learning!
sns.pairplot(penguin_df)
Not as easy!
EDA without hues quickly reveals to us the most likely number of clusters we might find if we used only pairs of inputs.
You are now on your own. Given this dataframe, extract the columns without the labels (bill_length_mm, bill_depth_mm, flipper_length_mm, body_mass_g), put those into arrays, pass that to the clustering libraries and get scores. (Don’t forget steps like scaling…)
Can you tell how many penguins species there are using just clustering?
✅ Task: (8 points) Select two features of the penguins dataframe and use K-Means and DBSCAN to find clusters.
(4 points) K-Means: Make plots showing the Voronoi cells for k = [2, 3, 4] similar to the one in Fig 9-7 of your textbook (pg. 270). Look for the code in the book’s github repo or look at this code to help you make the plot. Make sure to indicate the center of the clusters. Label your axis and add titles.
(4 points) DBSCAN: Make a plot similart to Fig. 9-14 of your textbook (pg. 280) for two values of
eps. Look for the code in the book’s github repo or look at this code to help you make the plot. Make sure to differentiate between outliers and members of the cluster. Label your axis and add titles.
# Put your code here
✅ Questions: (4 points)
What two features best cluster the penguins dataset for K-Means and DBSCAN?
Which estimator (DBSCAN or K-Means) you think is better?
Put your answers here
✅ Task: (8 points) Now select all four features of the penguins dataset and use K-Means and DBSCAN to find clusters.
(6 points) Using K-Means:
(2 points) Make a plot of the silhouette score vs the number of clusters, e.g.
k = [2, 3, 4, 5].(4 points) Then make a silhouette diagram similar to Figure 9-10 of your textbook (pg. 272). Look for code from the book’s github repo or follow this link.
(2 points) Using DBSCAN: Make a plot of the silhouette score vs
eps.
# Put your code here
✅ Questions: (6 points)
What is the best
kfor K-Means ?What is the best
epsfor DBSCAN ?Do the number of clusters predicted by K-Means and DBSCAN agree? Which algorithm do you think is best?
Put your answers here
Assignment wrap-up#
Please fill out the form that appears when you run the code below. You must completely fill this out in order to receive credit for the assignment!
from IPython.display import HTML
HTML(
"""
<iframe
src="https://forms.office.com/r/QyrbnptkyA"
width="800px"
height="600px"
frameborder="0"
marginheight="0"
marginwidth="0">
Loading...
</iframe>
"""
)
© Copyright 2023, Department of Computational Mathematics, Science and Engineering at Michigan State University.