Week 10: In-Class Assignment:
Gaussian Mixture Models#
✅ Put your name here.#
✅ Put your group member names here.
Gaussian Mixture Models#
You might want to skim your textbook on page 283 before you start this ICA. We didn’t cover GMMs in lecture, so you will learn about them today.
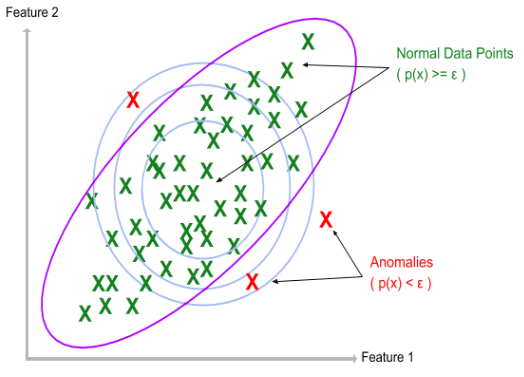
Earlier in the class we looked at using Gaussians and using them for doing simple anomaly detection. The basic idea was to use a multivariate Gaussian, which you can review here, that tells you where the probabilites are high and where they are low. As a reminder, look at the picture above.
This is an example of unsupervised learning because the data points have no labels, they are just points. As with clustering, we wish to only use their locations to organize them in some way. Fitting them to a multivariate Gaussian works pretty well.
But, as we saw with the various clustering algorithms, data often does not come to us as one “blob”. There may be many blobs, or lines, or circles or moons. How do we do anomaly detection with these cluster shapes?
GMMs are the obvious generalization of what we did earlier in the semester: if there are many clusters, use a mixture of Gaussians instead of just one.
This might look something like this:
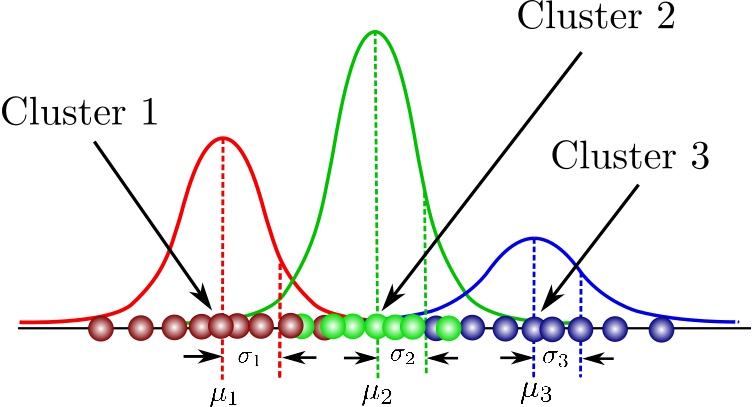
To make this more interesting, but still be able for our simple brains to visualize it, we’ll do this in 2D.
Before going further, you might quickly skim this notebook so that your group can divide and conquer. For example, 1-2 of you might write the multivaraite Gaussian function, 1-2 of you might work through the visualization, 1 person reads the textbook and so on…
In a sense, that is all there is to it. Of course, there are details. Go to this page in sklearn and read through the documentation.
✅ Questions: With your group, answer these questions:
What are the main options/inputs you need to provide to
sklearn’s GMM library?In particular, what is
covariance_type?Is
kmeansused in any way?What are the outputs? For example, what does
.means_give? What does.predictdo?weights_?As with the clustering algorithms, how would we select the number of components?
What are AIC and BIC (you will find these in the book)?
Discuss AIC and BIC with your group in more depth. In a markdown cell, explain how these could be used in other contexts. (They are extremely useful and arise in many contexts, most quite different from what we are doing today.)
1.2: Making Fake Data#
Ok, enough thinking about GMMs, let’s code them. First we need some data. We’ll use the usual sklearn tools for making fake data. (If you have some particular data you would rather use, feel free to do that.)
Write the code to make data at least five different ways, including options so that you can vary the size, shape and spread of the points.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.datasets import make_biclusters
from sklearn.datasets import make_checkerboard
from sklearn.datasets import make_circles
from sklearn.datasets import make_moons
num_points = 100
noise = 1.5
# Choose one of the datasets
X_data, y_labels = make_blobs(n_samples=num_points, centers = 2, n_features=2, cluster_std=noise, random_state=42)
# Uncomment the other dataset
# X_data, y_labels = make_moons(n_samples=num_points, noise=0.05 * noise, random_state=42)
Keep in mind that the sklearn libraries create the fake data to also be used with supervised classification. Here, we only use the labels as a guide to what sklearn was “thinking” when it made the fake data; otherwise, we don’t use the labels for unsupervised clustering. (Feel free to just ignore the labels and colors if you want to make this more realistic.)
Since we are examining anomaly detection, be sure you know how to control the noise levels within each make_ library.
plt.scatter(X_data[:,0], X_data[:,1], c=y_labels)
plt.xlabel("Feature 1")
plt.ylabel("Feature 2")
Next, let’s take this data and use the GMM to perform anomaly detection.
I give some example code here and there to get you started. You might want to generalize some of it. For example, you might want to make it work better for a given number of Gaussian components that you can loop over, both in terms of creating them and plotting them. You get the idea: make the code your own and more streamlined than the simple examples I give.
from sklearn.mixture import GaussianMixture
gmm_obj = GaussianMixture(n_components=2, random_state=0).fit(X_data)
print(f"\nThe means of the Gaussians in the GMM are:\n {gmm_obj.means_}.")
print(f"\nThe covariances of the Gaussians in the GMM are:\n {gmm_obj.covariances_}.")
print(f"\nThe weights of the Gaussians in the GMM are:\n {gmm_obj.weights_}.")
1.3: Visualization#
As we have seen before, the visualization can be the most tedious coding part…..
We have seen the minimal steps to create data and get basic results from the GMM. Before getting too far, let’s pause and think about how to visualize this. What you have seen is that GMM yields the means and covariances of how ever many components you asked for. To plot these with your data, you will need to take those outputs and construct the Gaussians. It is easy enough for you to construct those Gaussians using numpy.
✅ Do this: Write a function that accepts:
X, Y: which are 2D arrays created from
meshgrid,the mean of the Gaussian,
the covariance of the Gaussian,
and returns a 2D array of values. Using this array, you can plot that Gaussian. To plot the mixture, you can call this function as many times as you need to.
Hint: Using linalg you can write this function in just a couple of lines. Search the internet if you don’t have enough time to get that to work. Recall that we did this on the Pre-class assignment of Week 05.
Plot your Gaussians using contours over the data.
def multivariate_gaussian(X, Y, mean, cov):
# Put your code here
pass
# Put your code here
mean_1 = gmm_obj.means_[0]
mean_2 = gmm_obj.means_[1]
cov_1 = gmm_obj.covariances_[0]
cov_2 = gmm_obj.covariances_[1]
plt.scatter(X_data[:,0], X_data[:,1], c=y_labels)
The next step in the visualization is the contours.
Read about the options for contours, especially in terms of levels. In anomaly detection, we seek regions with low probability and it would be useful to be able to control contour lines to show that.
There are some nice examples here.
Another idea is to use a mask to find the outliers
Hint: If you get really stuck with visualization, look at your text and recall that all of the code is on Github.
Part 2. On Your Own#
Now it is time for you to play. Your final goal for today is to make an interesting plot and post it in the general Teams channel. Post a plot, one sentence of what it is, and your group number. Also, submit the notebook to D2L as usual.
Here are some ideas:
choose a new dataset (e.g. penguins, images, or the dataset for your project) and use GMM to find clusters
GMMs can be used for anomaly detection, so you can use all of the different ways of making fake data (with varying levels of noise and widely choosing contours) to examine what outliers look like in the GMM framework.
Also, GMM has a
.predict_method, which can be used for clustering (using AIC and BIC). An interesting use case would be this: can you spot outliers and also assign them to a cluster? That is, which points are outliers of which cluster?
You get the idea - be creative and have fun!
© Copyright 2023, Department of Computational Mathematics, Science and Engineering at Michigan State University.