Day 15 In-Class Assignment: (Thoughtfully) fitting models to data#
✅ Put your name here.
#✅ Put your group member names here.
#
In this assignment we’re going to look at how we might use a meaningful model to understand data.
The learning goals of the assignment are to:
Discuss the role that models play in our understanding of the world around us and how models can be used to make predictions.
Practice using the SciPy
curve_fit()function to fit a specific model to dataInterpret the results of our best fit model
Use our best fit model to calculate new values and forecast future behavior
Assignment instructions#
Work with your group to complete this assignment. Instructions for submitting this assignment are at the end of the notebook. The assignment is due at the end of class.
Image from: https://xkcd.com/2048/
1. Thinking about models and how they help us understand the world around us#
✅ In your groups, take turns providing examples of previous experiences you’ve had that involved a model (or models) of one form other another. These can be experiences from current or prior courses (outside of CMSE 201!) or experiences from your personal life or from work.
When sharing your example, you should:
Explain the real-world context of the model and what the basic components of the model are.
Identify and explain any assumptions that are built into the model or limitations of the model (i.e. where might the model breakdown?).
For example: I have a model for how my retirement savings will grow as a function of time and I can use this model to predict how much money I will have when I retire or to understand how early I might be able to retire given the financial needs I will have during my retirement. Assumptions that are built into my retirement model include things like the health of the economy over time and how much money (if any) I might receive from social security when I retire. The accuracy of my model is only as good as the assumptions I base it off of.
✅ Record the details you shared with your group in the cell below. There will be an opportunity to share out some of these examples as a class.
✎ Put your answer here
2. Using Python to fit specific models to data#
In the section that follows, we will practice using Python to fit a model to provided data. When doing so, it is important to think about whether or not these model fits the data well and what information about the data is provided by the model we use.
Revisiting population growth#
In a previous in-class assignment you created a function based on a model to project population growth as a function of time based on an initial population, a carry capacity, and a growth rate coefficient. Let’s quickly revisit the mathematical logistic growth model for growth of a population:
where
The variable \(C\) represents the carrying capacity of the population, which is the maximum population that the environment can sustain, and \(k\) is the relative growth rate coefficient (the larger \(k\) is, the faster the population will grow initially). \(P_{init}\) is the initial value of the population at \(t=0\).
Understanding a logistic growth model#
Here are several logistic growth models for when the initial population, \(P_{init}\), is 1 billion but the the carrying capacity, \(C\), and the growth rate coefficient, \(k\), are varied.
The first plot on the keeps \(P_{init}\) and \(k\) fixed while changing \(C\), and the second plot on the keeps \(P_{init}\) and \(C\) fixed while changing \(k\).
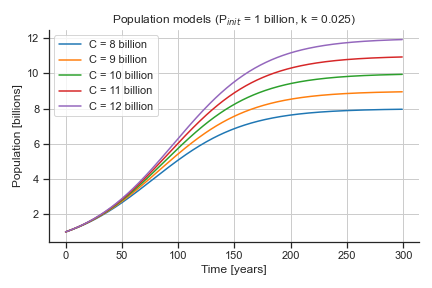
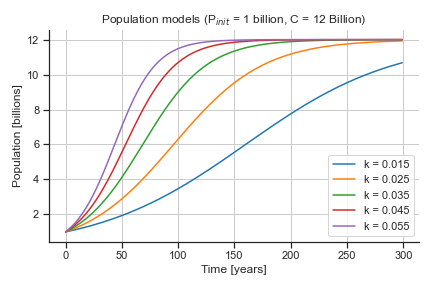
✅ Questions to make sure you answer with your group:
What is the impact of \(P_{init}\), the initial population, in the model? How would the curves change if you changed this value?
What is the impact of \(C\), the carrying capacity, in the model? How does this parameter control the shape of the curves in the plot above?
What is the impact of \(k\), the growth rate coefficient, in the model? How does this parameter control the shape of the curves in the plot above?
Pay special attention to the values for the parameters that made these curves – they may useful in the next part of the activity!
✎ Put your answers here.
Can we use this model to understand some population data?#
In the file, pop200.csv, you’ll find some data for 200 years of population growth for an unknown civilization.
✅ Your goal is to work with your group to determine if the population growth model presented above is a good approximation for the data that we’ve provided you and what the best fit parameters for that model are:
Load the data into your Jupyter notebook and make a plot of the data alone. Visualizing your data is always a good first step!
(Re)Create a function for calculating population as a function of time using the mathematical model provided above. You should have created such a model previously in the course!
Your function needs to take the following arguments in the following order: an array of time values; the initial population, \(P_{init}\); the carrying capacity, \(C\); and the growth rate coefficient, \(k\).
Your function needs to return an array of the population values.
For reference, here is the mathematical representation of the function again:
\[P(t) = \frac{C}{1 + Ae^{-kt}}\]where
\[A = \frac{C-P_{init}}{P_{init}}\]Note: the letters chosen to represent the model parameters have been changed slightly to avoid the confusion of having multiple “K” values. We’ll also assume that our model always starts at \(t=0\), so the model no longer needs a \(t_0\) parameter. Variations in how models are defined are common, and it’s good practice to adapt your code to match a modified model.
# Put your code here. Create additional code cells as is useful for necessary
Now let’s use curve_fit!#
Use SciPy’s
curve_fitfunction to determine a best fit set of model parameters using your function and the provided data. Note: When you first try runningcurve_fit(), you might get a warning, and you might get results that don’t make sense. Sometimescurve_fitwill fail to find a good fit if the initial guess for the best fit parameters is too far off.Why might this happen? When you use
curve_fit, it will try many different combinations of values to find which set of parameters fit the data best. Therefore, we have to givecurve_fitsome initial values for the fit parametersHow would you fix this? Look at the documentation for
curve_fit, especially thep0argument, and see if you and your group can figure out how to overcome this issue. What might be reasonable starting guesses for the initial population and the carrying capacity? Hint: revisit the plot from above and the parameters that were used to make those models.What if it still isn’t working? When you are setting up a call to
curve_fit, the inputs are what are called positional arguments. That means thatcurve_fitexpects the inputs to be in a particular order! Make sure that you have your arguments in the correct order and that the function you wrote for population as well as yourp0values are all in the same order!
Make a plot of the data as well as the expected values based on your best fit model parameters.
Your plot should plot population (in billions) on the y-axis and time (in years) on the x-axis. Make sure you include appropriate axis labels.
Your plot should use a legend to identify what parts of the plot constitute the data and what part represents the expected values from your model.
Interpreting your results and using your model to calculate expected values.#
✅ Now that you’ve modeled the data using your logistic growth model, use your results to answers the following questions.
What does your model estimate as being the initial population for this civilization?
What does your model estimate as being the carry capacity of the population?
Using your model and the best fit parameters, calculate the expected population for this civilization at:
177 years
256 years
Ask your group for help if you’re not sure how to find these answers.
✎ Put your answers here.
# Or use code to print out your answers
Using your model to forecast future values#
✅ Using your model and the best-fit parameters, generate a new plot that shows the expected values for every year for the first 300 years of the civilization. Overplot the data you have for the first 200 years of growth.
# Put your code here
Comparing forecasted values to new data#
✅ Now that you’ve predicted the growth of the population for a full 300 years, grab the pop300.csv data file which contains the most recent data available for this civilization, read it into your notebook and plot it along with your expected values.
# Put your code here
✅ Question: Do you still feel like the model is a good fit to the population data for this civilization? Explain why or why not. Are their any parameters of your model that seem particularly inaccurate given the new data?
✎ Put your answer here.
Updating your model based on new data#
Regardless of whether or not you think your current model is a good fit to the data, it’s always worth checking to see if the new data provides a different set of best fit parameters. Folks who build and use models to understand the world around them are constantly using new data to revise and improve their models.
✅ Try recalibrating your best fit parameters by running curve_fit on the new data you’ve been provided. Then answer the following questions:
Which parameter(s) changed the most when you re-fit your model to the data?
Do any shifts you find in the parameter values agree with your “by eye” assessment of how well the model fit the data? Explain why or why not.
# Put your code here
✎ Put your answer here.
✅ Now that you have a new set of best fit parameters, make one final plot that shows the true glory of your expected model values along with the full set of data.
# Put your code here.
Assignment wrapup#
Please fill out the form that appears when you run the code below. You must completely fill this out in order to receive credit for the assignment!
from IPython.display import HTML
HTML(
"""
<iframe
src="https://cmse.msu.edu/cmse201-ic-survey"
width="800px"
height="600px"
frameborder="0"
marginheight="0"
marginwidth="0">
Loading...
</iframe>
"""
)
Congratulations, you’re done!#
Submit this assignment by uploading your notebook to the course Desire2Learn web page. Go to the “In-Class Assignments” folder, find the appropriate submission link, and upload everything there. Make sure your name is on it!
© Copyright 2024, Department of Computational Mathematics, Science and Engineering at Michigan State University.