Day 10 In-Class: Cleaning and Analyzing Economic Data#
✅ Put your name here
#✅ Put your group member names here.
#
Goals for today’s in-class project#
Load in data and clean Pandas dataframes
Learn different ways to index Pandas dataframes
Analyze different countries GDP data
Practice using online research to learn new programming skills
Assignment instructions#
Work with your group to complete this assignment. The assignment is due at the end of class and should be uploaded to the appropriate submission folder on D2L.
Part 1: Practice calculating statistics using Python#
1.1 Computing standard deviation by hand#
✅ Fix the following function which is supposed to take in a list of values and calculate the standard deviation using only basic python functions. The function is already written but it doesn’t quite work. Run the cell to see. Here’s the equation for standard deviation:
$\( \sigma = \sqrt{\frac{\sum\limits_{i=1}^{N} (x_{i}-\mu)^2}{N}} \)$#
where the symbols in this equation represent the following:
\(\sigma\): Standard Deviation
\(\mu\): Mean
\(N\): Number of observations
\(x_{i}\): the value of dataset at position \(i\)
You may want to check in with your group to make sure you understand the notation in this equation!
# Fix this function to make sure it correctly calculates the standard deviation
def std(vals):
length = len(vals)
mean = sum(vals)
diffs = []
for i in range(length):
diffs.append(vals[i] - mean)
return sum(diffs)**0.5
✅ Check your function for accuracy
Call your function using the variable test_list (provided below) as the input and compare your function’s output with that of np.std() to make sure you calculated standard deviation correctly.
import matplotlib.pyplot as plt
import numpy as np
test_list = [1,3,5,10,15,5]
# Put your code for comparing the answers here
1.2 Next, we will apply stats to a distribution visually#
But first, let’s cover how to visualize the distribution of a one-dimensional data set. We begin with a random distribution of numbers from a random number generator in the NumPy library.
# You might not be familiar this with random number generator, that's OK,
# This is one of _many_ that are available in NumPy.
random_distribution = np.random.wald(200,500,size=1000)
This is an array holding 1000 random numbers, generated from a statistical distribution called the “Wald distribution” (or “inverse gaussian distribution”).
Let’s look at the first 10 numbers. Take special notice of how we are “slicing” the array to get just a subset of the values using “:”!
# Run this cell!
random_distribution[0:10]
array([156.93904053, 148.91980681, 63.21062257, 75.70183436,
159.79905634, 119.57298849, 276.93696695, 133.79100521,
98.41080745, 75.39784443])
And now let’s make a plot all of the elements:
# Run this cell!
plt.plot(random_distribution,'o')
plt.xlabel('Index')
plt.ylabel('Value')
Text(0, 0.5, 'Value')
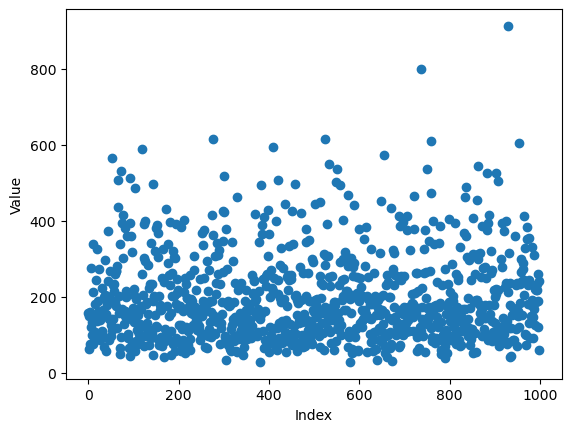
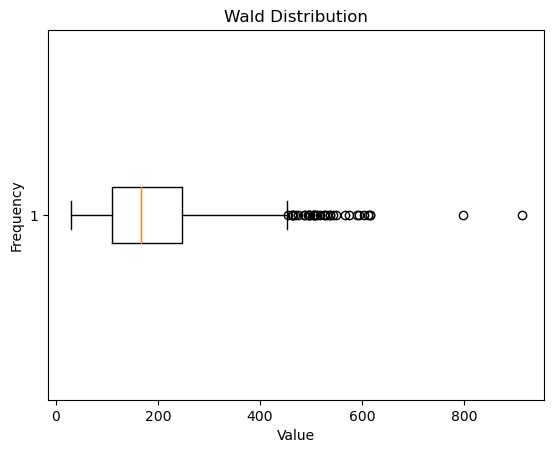
What are some other ways we can analyze and visualize this data? One visualization is a box plot, which shows where the quartiles of the data set are, as well as outliers.
# Run this cell!
box = plt.boxplot(random_distribution, vert=False)
ylabel = plt.ylabel("Frequency")
xlabel = plt.xlabel("Value")
title = plt.title("Wald Distribution")
Another visualization is a histogram, which splits the data set into a bunch of equally sized intervals, and then graphs the number of data points that fall into each interval. The higher the bar on a histogram, the more data points in that interval. Thought of another way, a histogram shows you the “count” or “frequency” of values falling into a specific bin on the x-axis.
# Run this cell!
hist = plt.hist(random_distribution, bins=50, color="k", alpha=0.5) #what's the alpha argument doing?
ylabel = plt.ylabel("Frequency")
xlabel = plt.xlabel("Value")
title = plt.title("Wald Distribution")
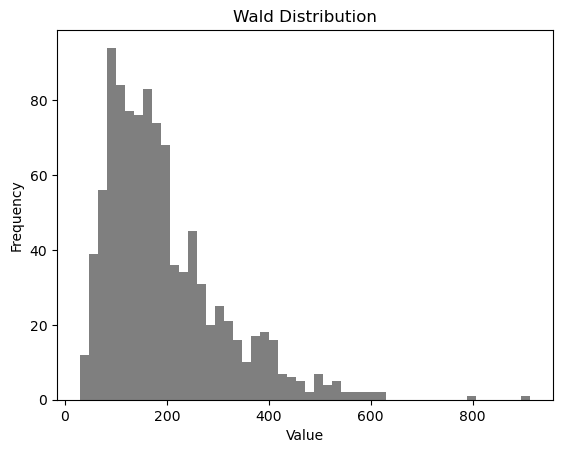
✅ Compare the representations above
What are the similarities between how the boxplot represents the data set versus the histogram? What does the boxplot do a better job of showing? What does the histogram do a better job of showing?
✎ Put your answer here
1.3 Compute and Compare#
✅ Now lets actually compute the mean and median and visualize them on the distribution graph.
Add two vertical lines with different colors where the mean and median are using Matplotlib’s plt.axvline() function – this might be new to you, so make sure you understand how it works!
Make sure you label your lines and include a legend.
hist = plt.hist(random_distribution,bins=50,color="k",alpha=0.5)
# Add your additional plotting commands here
# The following line is provided to help get you started, you need to decide what to use for the "x" argument
#plt.axvline(x=?,linewidth=2, color='r',label = "Median")
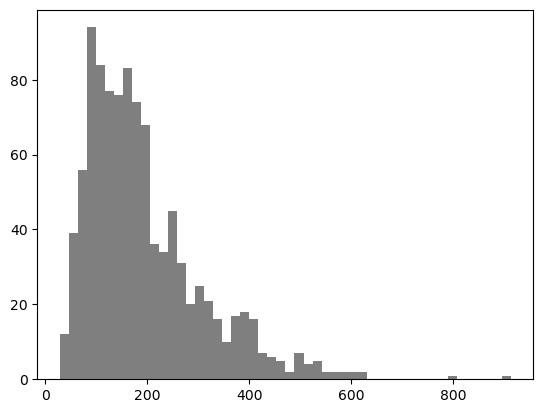
✅ Which is larger for this data set, mean or median? Explain why you think that is.
✎ Put your answer here
Part 2: Loading in and cleaning economic data#
The next part we will focus on transforming and manipulating a dataset using Pandas. As data scientist/computational professional in training, one of the goals we want you to accomplish is to be comfortable searching through online resources to try and solve problems. There are far too many functions and concepts in programming to remember everything so in practice it’s essential to utilize package documentation, stack overflow, etc. Some of the questions you will see below will ask you to use or look for a function you’ve never used before to get you to practice Googling questions that help you accomplish your task.
What data are we working with?#
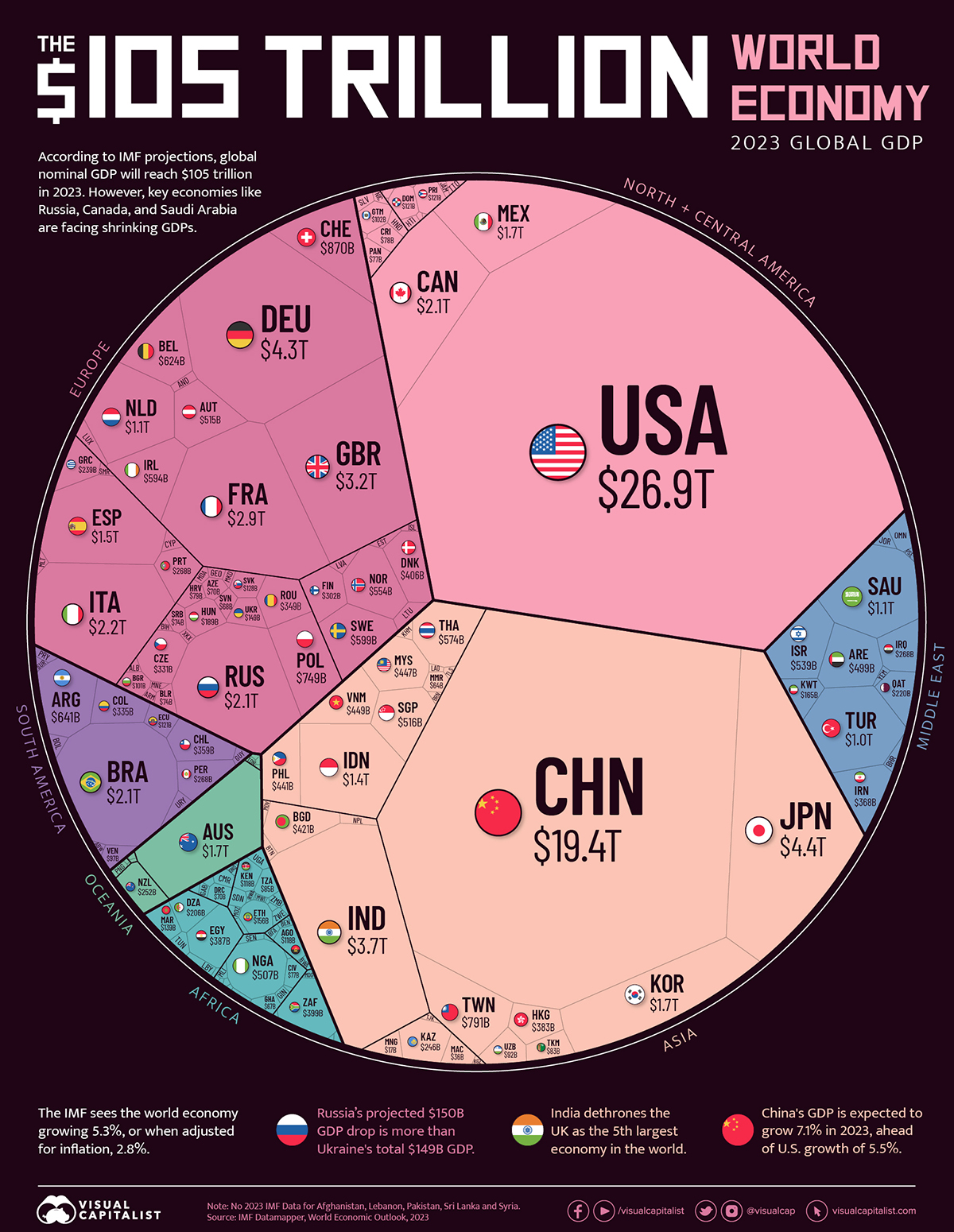
We will be analyzing a dataset from the World Bank containing yearly GDP data for countries from 1960-2023. The GDP numbers have been converted to USD for all countries by the exchange rate at the time. Which is important to note because depending on the exchange rates at the time this could over/under value the non US countries numbers or increase the variance of GDP.
The dataset comes from here: https://data.worldbank.org/indicator/ny.gdp.mktp.cd
GDP stands for Gross Domestic Product and it is equal to the market value of all the finished goods and services produced within a country’s borders in a specific time period.
GDP = Consumer Spending + Private Investment + Government Expenditure + Net Exports
2.1 Cleaning data is an important part analyzing data.#
First, we’re going to load in the .csv dataset into a Pandas Dataframe and explore the original structure of the data and think about if it could be formatted in a more useful way. If you were to download the data from the website, you might end up with more than one .csv file, we’ve provided the one that contains the GDP information on the course website.
Make sure you import the Pandas module before moving on!
# put your Pandas import command here
✅ Load in the API_NY.GDP.MKTP.CD_DS2_en_csv_v2_31795.csv file using pd.read_csv(). Skip the first 4 rows and use a comma as the delimiter. Then display the first few lines using .head().
Use gdp as the variable name for storing your dataframe as indicated in the code cell below.
# Load in GDP.csv
#gdp = # Finish this line to load in the data!
As a first step to cleaning a data set, it can be helpful to get rid of rows that have a lot of “NaN” values. NaN means “Not a Number,” and it is a value that sometimes takes the place of a blank entry. Countries that did not track GDP as far back as 1960 will have some NaN values, such as Aruba and Angola. You may want to keep these rows in your own data sets, but for this assignment, we are going to “drop” them from the data set, using a handy pandas function called “dropna”.
Important note: sometimes when you use Pandas function is modifies your dataframe directly, but other times it generates a new dataframe based on the old one. When the function returns a new dataframe, we need to make sure we store that result in a variable. Look carefully at the code below to see how this is being done.
gdp = gdp.dropna(axis="columns", how="all") # drop empty columns, like the last column in gdp
gdp = gdp.dropna() # drop rows with NaNs, like Aruba and Angola
gdp.head()
| Country Name | Country Code | Indicator Name | Indicator Code | 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | ... | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Africa Eastern and Southern | AFE | GDP (current US$) | NY.GDP.MKTP.CD | 2.121696e+10 | 2.230747e+10 | 2.370247e+10 | 2.577938e+10 | 2.804954e+10 | 3.037491e+10 | ... | 9.796897e+11 | 8.992957e+11 | 8.298300e+11 | 9.401055e+11 | 1.012719e+12 | 1.006527e+12 | 9.290741e+11 | 1.086772e+12 | 1.183962e+12 | 1.236163e+12 |
| 3 | Africa Western and Central | AFW | GDP (current US$) | NY.GDP.MKTP.CD | 1.188413e+10 | 1.268566e+10 | 1.360683e+10 | 1.443998e+10 | 1.576911e+10 | 1.693448e+10 | ... | 8.945854e+11 | 7.693673e+11 | 6.921811e+11 | 6.857502e+11 | 7.681896e+11 | 8.239336e+11 | 7.871467e+11 | 8.459930e+11 | 8.771408e+11 | 7.965862e+11 |
| 13 | Australia | AUS | GDP (current US$) | NY.GDP.MKTP.CD | 1.860656e+10 | 1.968288e+10 | 1.992256e+10 | 2.153984e+10 | 2.380112e+10 | 2.597616e+10 | ... | 1.468598e+12 | 1.351769e+12 | 1.207581e+12 | 1.326882e+12 | 1.429734e+12 | 1.394671e+12 | 1.330382e+12 | 1.559034e+12 | 1.692957e+12 | 1.723827e+12 |
| 14 | Austria | AUT | GDP (current US$) | NY.GDP.MKTP.CD | 6.650134e+09 | 7.375455e+09 | 7.823687e+09 | 8.447137e+09 | 9.249879e+09 | 1.008115e+10 | ... | 4.425848e+11 | 3.819711e+11 | 3.958374e+11 | 4.172612e+11 | 4.549912e+11 | 4.445962e+11 | 4.350493e+11 | 4.792954e+11 | 4.709419e+11 | 5.160341e+11 |
| 16 | Burundi | BDI | GDP (current US$) | NY.GDP.MKTP.CD | 1.960000e+08 | 2.030000e+08 | 2.135000e+08 | 2.327500e+08 | 2.607500e+08 | 1.589950e+08 | ... | 2.705783e+09 | 3.104004e+09 | 2.644488e+09 | 2.723587e+09 | 2.667182e+09 | 2.576519e+09 | 2.649680e+09 | 2.775799e+09 | 3.338723e+09 | 2.642162e+09 |
5 rows × 68 columns
Note that the dropna function was accessed from the dataframe itself (gdp.dropna()). These functions are included with each dataframe object. We’ve already seen this with functions like describe(), and even with numpy array functions like my_array.sum(). Many of the functions you’ll be using today are included with the dataframe objects.
You can browse through these built-in functions by typing the name of a dataframe followed by . and then hitting the tab key. Try it out below!
# uncomment the line below, then go to the end of the line and hit tab
#gdp.
If you want to learn more about something, select it (or type it out), add a question mark (?) and then run the cell. Ask an instructor for help if you can’t get the ? mark trick to work!
Making the dataset easier to explore#
Typically when we are looking at data over time we represent each time step as a row rather than a column. Switching the rows and columns is an operation known as “Transposing” and Pandas has a function that does that!
IMPORTANT: When you use Pandas functions on dataframes, some operations will affect the original dataframe (referred to as “in place” operations), and some will not (referred to as “not in place” operations). Transposing a dataframe is a not in place operation, meaning that the results are not saved unless you save them to a variable!
Let’s transpose the dataset to get years as rows instead of columns.
Example of Transposing:
✅ Transpose the data to flip the orientation of the rows and columns.
# Transpose the dataframe here and check to see if it worked
# MAKE SURE YOU SAVE YOUR TRANSPOSED DATAFRAME AS A VARIABLE
One of the benefits of Pandas Dataframe is being able to index a column by name rather than a number.
✅ Modify the dataframe so that each country name is used as the column headers by assigning the first row of the dataframe to be the column headers.
Think back to the Pre-Class Assignment. What information are you looking to retrieve? What tools do you have to access this information? You may want to use .iloc to do this. If done correctly, you then should be able to index a column out of our dataframe using gdp['United States'], for example. Make sure to test this out!
# Change the column headers to be the country names here.
This is looking pretty good!
Of course, now we have a few redundant rows: “Country Name”, “Country Code”, “Indicator Name”, and “Indicator Code”. We don’t really need these any more now that we’ve change the column labels.
✅ Remove these four rows, since they don’t contain yearly GDP data. There’s more than one way to do this. The best option is to use the gdp.drop() function. Figure out how it works with gdp.drop?.
# Try to remove the rows that don't represent years here
Now our dataset should be in an easier format. The next step is to examine the structure of our data.
✅ Review the following code and comment what each line is doing.
print(gdp.index) #comment here
print(type(gdp.index[0])) #comment here
Index(['1960', '1961', '1962', '1963', '1964', '1965', '1966', '1967', '1968',
'1969', '1970', '1971', '1972', '1973', '1974', '1975', '1976', '1977',
'1978', '1979', '1980', '1981', '1982', '1983', '1984', '1985', '1986',
'1987', '1988', '1989', '1990', '1991', '1992', '1993', '1994', '1995',
'1996', '1997', '1998', '1999', '2000', '2001', '2002', '2003', '2004',
'2005', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013',
'2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022',
'2023'],
dtype='object')
<class 'str'>
We can see the index column is made up of strings representing years, which isn’t ideal!
The code below will change the data type from strings to integers. This will be helpful for when we begin plotting because when you try to plot strings as numbers it doesn’t usually work out very well!
gdp.index = gdp.index.astype(int)
gdp.index
Index([1960, 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969, 1970, 1971,
1972, 1973, 1974, 1975, 1976, 1977, 1978, 1979, 1980, 1981, 1982, 1983,
1984, 1985, 1986, 1987, 1988, 1989, 1990, 1991, 1992, 1993, 1994, 1995,
1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007,
2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019,
2020, 2021, 2022, 2023],
dtype='int32')
2.2 Exploring the Data#
✅ Now pick 2 countries and print the GDP for year 1975 using .loc and the column name. Again, look back at the dataset and think about what information we are looking to retrieve. What information is stored in our columns? What information is stored in our rows?
# Put your code here
✅ Now, plot those two countries GDP in billions of dollars from 1960-2020, make sure to have proper labels and legends.
# Put your plotting commands here
✅ Question Is this a good way visual comparison for the two countries? If one country has a much larger GDP or much larger population than the other country what would be a better way to normalize or compare the data? This might involve doing some sort of calculation or visualizing the data differently.
✎ Put your answer here
2.3 Exploring the log-linear plot#
During the COVID-19 pandemic, some of the visualizations floating around that show the numbers of confirmed cases in various places around the world have been “log-linear” plots which uses a logarithmic scale (tick marks indicate powers of 10) on the y-axis and a linear scale on the x-axis. Some folks have even written papers about how these sort of plots may or may not impact how people perceive the need for confinement to stop the spread of the virus.
You can change the scaling of an axis for a matplotlib plot using plt.yscale('log'). Or, you can try using the plt.semilogy() function.
✅ Try using a log scale for the GDP in the previous plot for the two different countries to see if it facilitates a better comparison!
# Try making a "semilogy" plot here or try use the `plt.yscale()` function to modify your plot
✅ Question Do you find this to be a better way to visualize the data, yes or no? Explain your reasoning!
✎ Put your answer here
2.4 Analyzing growth rates#
One way to compare GDP between different countries in a way that is unit free would be to consider the countries growth rates. The growth rate for a year would be equal to the percent change going from one year to another, defined like so:
Growth Rate in 1961 = (GDP in year 1961 - GDP in year 1960) / GDP in year 1960
✅ Lets plot two countries growth rates on the same plot over time making sure to properly label our graph.
(Hint: Pandas dataframes might have a function that can compute the percent change for you – time to consult the internet again!)
# Calculate and plot the growth rates as a function of time
✅ Question: Why might comparing growth rates be a better comparison for countries that have GDP’s of very different magnitudes?
✎ Put your answer here
More Data Manipulation (time permitting or if you’re interested in exploring the data further on your own time!)#
Filtering, sorting, and calculating new quantities#
You’ve been able to clean, transform, and visualize the data, but for an extra challenge let’s use any time you have remaining to work on filtering and sorting your data.
The below analyses are going to focus on data for individual countries for the year 2020. To get started, we’re going to:
create a new dataset for only the year 2023, and
drop columns that don’t correspond to individual countries
gdp2023= gdp.loc[2023]
gdp2023 = gdp2023.drop(['World', 'High income', 'OECD members', 'Post-demographic dividend', 'IDA & IBRD total',
'Low & middle income', 'Middle income', 'IBRD only', 'Upper middle income',
'North America', 'Late-demographic dividend',
'East Asia & Pacific',
'East Asia & Pacific (excluding high income)',
'East Asia & Pacific (IDA & IBRD countries)', 'Euro area', 'Early-demographic dividend',
'Lower middle income', 'South Asia',
'South Asia (IDA & IBRD)', 'IDA total',
'Sub-Saharan Africa', 'Sub-Saharan Africa (IDA & IBRD countries)',
'Sub-Saharan Africa (excluding high income)', 'IDA only','Europe & Central Asia', 'European Union','Fragile and conflict affected situations'])
✅ Great! Now filter the top 10% of countries in the cleaned up data set by their 2023 GDP, print their names, and store the names in a list in ordered by their GDP ranking.
(Hint: Pandas has a quantile function that could be useful to find the value for the 10% cut off as well as a function for sorting the values)
# Put your code for finding the countries with the highest 10 GDP values and sorting them here
✅ Let’s take a closer look at how the countries rank by plotting a horizontal bar graph of the top 10% countries GDP in billions by ranking order starting with the highest GDP.
Pandas dataframes have a horizontal bar graph function as well (.plot.barh()) – isn’t Pandas handy?
# Make your horizonal bar graph here
✅ With Pandas, we can pull multiple columns at the same time. Using that list of the top 10% of countries, create a subset of the original GDP dataframe that has data for only the last 20 years for countries in your list of top 10%.
We can create a subset by setting a new variable to equal the subset of the Dataframe.
(something like: Subset = DataFrame[list_of_columns_headers])
# Put your code here and create additional code cells as needed
✅ Next, calculate the standard deviation of GDP for each country in the subset dataframe over the last 20 years. Recreate the Horizontal Bargraph above with but using the standard deviation.
✅ Are there similiarities between the GDP graph and the standard deviation graph? Explain why you think they look similiar and what the limitation is with using standard deviation to compare the variation of the GDP for different contries.
✎ Put your answer here
Let’s pause and think about the following example:
X = np.array([2,4,10,15,30,50])
print(np.std(X))
X2 = X*50
print(np.std(X2))
16.79037422652237
839.5187113261185
The idea here is the spread between the numbers in the datasets X & X2 are the same in when considered as a percentage of the total, but the standard deviation will be proportionally higher for X2. This means the difference between each observation and the mean from a percentage basis is the same, but because the values in X2 are 50 times larger, the standard deviation will be 50 times larger.
The take away is if we want to compare how much a countries GDP growth varies relative to another country, we want an apples to apples comparison. For example, taking the standard deviation of the United States compared to Thailand we would expect United States to have a higher standard deviation because the US GDP is much higher. When in reality, Thailand’s GDP varies relatively more than the United States GDP varies.
In order to compare the variation in GDP by countries of different magnitudes we want to be looking at the change in GDP from a percentage view.
✅ Recreate the horizontal bar graph again, but this time take the standard deviation of the percent changes, or growth rates, of GDP for the last 20 years.
# Put your code here
✅ What do you observe? Why is taking the standard deviation of growth rates a better assessment of volatility than standard deviation of normal GDP for this data?
✎ Put your answer here
Assignment wrapup#
Please fill out the form that appears when you run the code below. You must completely fill this out in order to receive credit for the assignment!
from IPython.display import HTML
HTML(
"""
<iframe
src="https://cmse.msu.edu/cmse201-ic-survey"
width="800px"
height="600px"
frameborder="0"
marginheight="0"
marginwidth="0">
Loading...
</iframe>
"""
)
Congratulations, you’re done!#
Submit this assignment by uploading your notebook to the course Desire2Learn web page. Go to the “In-Class Assignments” folder, find the appropriate submission link, and upload everything there. Make sure your name is on it!
© Copyright 2024, The Department of Computational Mathematics, Science and Engineering at Michigan State University.