Pre-class Assignment: Intro to Machine Learning#
Day 15#
CMSE 202#
✅ Put your name here
#Goals for today’s pre-class assignment#
Define machine learning and describe the seven steps used to build machine learning models of data.
Explain what a classification problem is, and the concepts of false positives and false negatives.
Make a data set that could be used for classification and plot the data
Assignment instructions#
This assignment is due by 11:59 p.m. the day before class and should be uploaded into the appropriate “Pre-class assignments” submission folder in the Desire2Learn website.
Imports#
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
1. A quick introduction to machine learning#
In this assignment, we’ll begin our dive into “Machine Learning” (ML). You may have heard the term thrown about before, but might not entirely understand what it is or how it is used.
The two videos included below should give you a basic understanding for what machine learning is and how it is used.
Watch the videos and answer the questions.
from IPython.display import YouTubeVideo
YouTubeVideo("HcqpanDadyQ",width=640,height=360)
✅ Question 1 : List three examples of machine learning in our world today.
✎ Do This - Erase the contents of this cell and replace it with your answer to the above question! (double-click on this text to edit this cell, and hit shift+enter to save the text)
✅ Question 2: According to video, what is the definition of machine learning?
✎ Do This - Erase the contents of this cell and replace it with your answer to the above question! (double-click on this text to edit this cell, and hit shift+enter to save the text)
from IPython.display import YouTubeVideo
YouTubeVideo("nKW8Ndu7Mjw",width=640,height=360)
✅ Question 3: Why might it be important to seperate the testing data from the training data ?
✎ Do This - Erase the contents of this cell and replace it with your answer to the above question! (double-click on this text to edit this cell, and hit shift+enter to save the text)
✅ Question 4: Why is it important to prepare data before putting it in to a model?
✎ Do This - Erase the contents of this cell and replace it with your answer to the above question! (double-click on this text to edit this cell, and hit shift+enter to save the text)
✅ Question 5: The video is about the “7 Steps of Machine Learning”. Those steps are reproduced below. In your own words, try to explain what each of those steps involve with a sentence or two.
✎ Do This - Fill out the 7 Steps of Machine Learning:
Gathering data involves…
Preparing that Data involves…
Choosing a Model involves…
Training involves…
Evaluation involves…
Hyperparameter Tuning involves…
Prediction involves…
2. Various kinds of machine learning#
There are lots of different kinds of machine learning out there. You might only associate ML with the kind of deep neural networks you see discussed by Google. But there are many kinds. Look at the image below:
See anything that looks familiar? Regression is a whole category and OLS is one kind of machine learning. The diagram above is based on algorithmic approaches but here is another based on the process:
✅ Do this: Watch the following video that provides an overview about “Regression” and “Classification” in the context of Machine Learning while also highlighted the differences between supervised and unsupervised machine learning.
from IPython.display import YouTubeVideo
YouTubeVideo("TJveOYsK6MY",width=640,height=360)
✅ Question 6: Look up the terms “Supervised”, “Unsupervised” and “Reinforcement” Learning. Provide a brief definition of each below. You could of course copy definitions from somewhere, but do your best to see if can put them in your own words.
✎ Supervised learning is:
✎ Unsupervised learning is:
✎ Reinforcement learning is:
3. Classification#
Classification represents a group of algorithms that map observations (features) into class labels. We’ve seen examples of classification before. The Iris data set is an example of mapping a set of observations, 4 features per observation, into one of three class labels, in particular Iris type. It’s easy to imagine many applications and there are multiple algorithms focus on the classification task.
Classification is a supervised learning task. One of the principal concerns we have for a classifier is how often it makes mistakes (i.e., false positives and false negatives relative to its true predictions)
✅ Do this: Watch the following video for an overview of what is meant by a “false positive” or “false negative”.
from IPython.display import YouTubeVideo
YouTubeVideo("Ivc8c9ijWIQ",width=640,height=360)
✅ Question 7: After watching this video explain in your own words the concepts of false positives and false negatives. Feel free to use your own examples.
✎ Do This - Erase the contents of this cell and replace it with your answer to the above question! (double-click on this text to edit this cell, and hit shift+enter to save the text)
3.1 Making some data#
We spend a lot of time reading in data but sometimes it is easier to generate some data, under our control, and see what we get. To get a better handle on how easy/hard classification might be, we can use the function make_classification
This function is part of the sklearn library, which is the standard for machine learning in python, much like pandas is the standard for data handling. We have used statsmodels in the past, mostly for its improved statistical properties, but sklearn is a big, broad, and well maintained library. We will use it in future assignments and you will likely encounter it in any future data science endeavours.
Take a look at the make-classification documentation. It has a lot of parts but most are fairly clear:
how many samples
how many features
how many of those features are:
informative
redundant (basically random noise)
repeated (some combo of informative and redundant)
number of classes (how many labels)
It returns two values: an array of shape(n_samples, n_features) and the integer labels (the class they belong to) for each sample.
You can look at the rest of the arguments for the function and make intentional choices about what you want them to be or you can just use the defaults (at least for now).
Let’s start by making a scatter plot of a sample of data with 3 features including 1 that is redundant with only 1 cluster per class (i.e., 1 grouping per labeled class). Because we have 3 features, we should look at scatter plots of each pair of features. Note that we use c=class_labels to send class_labels to the color attribute, which colorizes different classes.
✅ Do this: Review the following code and the resulting plots, make sure you understand what the code is doing! You might want to run the cell a few times to see how the answers chance this the make_classification function relies on a random number generator.
features, class_labels = make_classification(n_features = 3, n_redundant = 1, n_clusters_per_class=1)
f, axs = plt.subplots(3,1,figsize=(12,12))
plt.subplot(311)
plt.scatter(features[:, 0], features[:, 1], marker = 'o', c = class_labels, ec = 'k')
plt.xlabel('feature 0')
plt.ylabel('feature 1')
plt.subplot(312)
plt.scatter(features[:, 1], features[:, 2], marker = 'o', c = class_labels, ec = 'k')
plt.xlabel('feature 1')
plt.ylabel('feature 2')
plt.subplot(313)
plt.scatter(features[:, 0], features[:, 2], marker = 'o', c = class_labels, ec = 'k')
plt.xlabel('feature 0')
plt.ylabel('feature 2')
✅ Question 8: Given your plots (you might run the code a few times) and the sklearn documentation, what does a “redundant feature” appear to be?
✎ Do This - Erase the contents of this cell and replace it with your answer to the above question! (double-click on this text to edit this cell, and hit shift+enter to save the text)
3.2 Plot some examples#
Some data are easier to classify than others. You might remember this from the work we did with the iris data set earlier in the semester. As a reminder, we include a plot of the iris data set below along with the classfication of each sample.
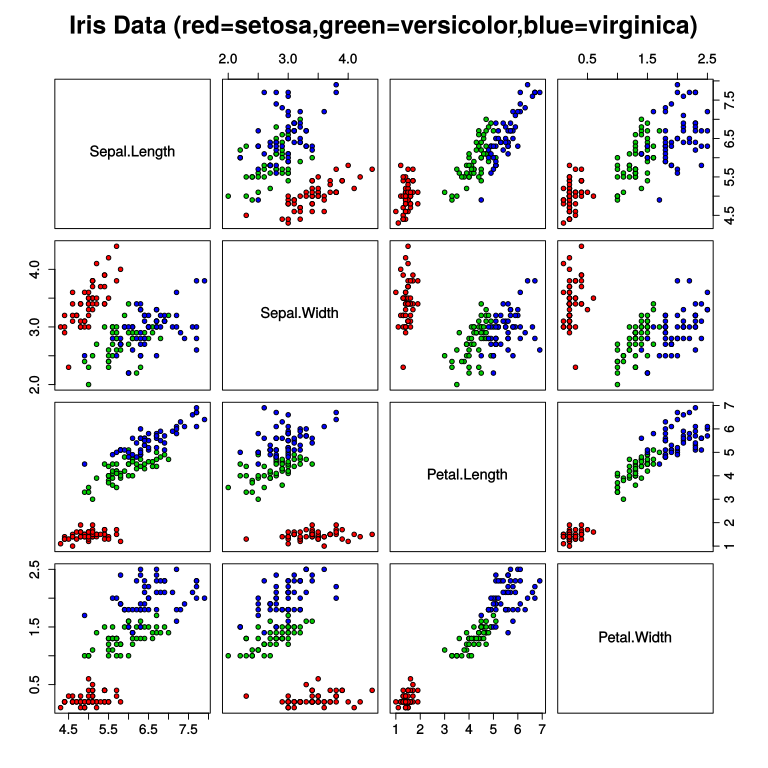
Let’s plot some examples of made-up data to explore in what way we might find it easier or difficult to classify that data. Try generating the following:
100 samples (that’s the default), 2 features, no redundant features, one informative feature, one cluster per class
100 samples (that’s the default), 2 features, no redundant features, two informative features, one cluster per class
100 samples (that’s the default), 4 features, two redundant features, two informative features, one cluster per class
100 samples (that’s the default), 4 features, two redundant features, two informative features, two clusters per class
Make a scatter plot of these data. For the data with 4 features, you might want to look at different pairs of features before answering the question below.
# your code here
✅ Question 9: Given the plots here (again, you may need to visualize the results a few different times to see how things change), which of these would be easiest to classify? Why? You might think back to the iris data set if it helps.
✎ Do This - Erase the contents of this cell and replace it with your answer to the above question! (double-click on this text to edit this cell, and hit shift+enter to save the text)
4. Getting Started with Classification: Logistic Regression#
There are variety of classifiers out there, we will explore some of them in this class. Since we’ve already spent some time thinking about regression in class, we will start with one of the most widely used classifiers: Logistic Regression. The video below provides a conceptual explanation of the technique.
from IPython.display import YouTubeVideo
YouTubeVideo("yIYKR4sgzI8",width=640,height=360)
✅ Question 10: Think about a siutation where you might want to classify some set of things using logistic regression. What is that set? What are the classes? And what kinds of features would you use to build that model?
✎ Do This - Erase the contents of this cell and replace it with your answer to the above question! (double-click on this text to edit this cell, and hit shift+enter to save the text)
Follow-up Questions#
Copy and paste the following questions into the appropriate box in the assignment survey include below and answer them there. (Note: You’ll have to fill out the assignment number and go to the “NEXT” section of the survey to paste in these questions.)
In your own words, provide a brief definition of supervised, unsupervised, and reinforcement learning. (you should be able to copy your answer to Question 6 from Part 2).
What was your example for a situation where you might use logistic regression to classify something? (from Question 10 in Part 4).
5. Assignment wrap-up#
Please fill out the form that appears when you run the code below. You must completely fill this out in order to receive credit for the assignment!
from IPython.display import HTML
HTML(
"""
<iframe
src="https://cmse.msu.edu/cmse202-pc-survey"
width="800px"
height="600px"
frameborder="0"
marginheight="0"
marginwidth="0">
Loading...
</iframe>
"""
)
Congratulations, you’re done with your pre-class assignment!#
Now, you just need to submit this assignment by uploading it to the course Desire2Learn web page for today’s submission folder (Don’t forget to add your names in the first cell).
© Copyright 2024, Department of Computational Mathematics, Science and Engineering at Michigan State University