Pre-Class Assignment: Pandas Review#
Day 5#
CMSE 202#
✅ Put your name here
#Goals for today’s pre-class assignment#
Reviewing the basics of Pandas
Reviewing Pandas Dataframes
Assignment instructions#
Watch any videos below, do any of the associated readings, and complete the assigned programming problems. Please get started early, and come to office hours if you have any questions! You should also use Slack to help each other thought any issues you run into!
Recall that to make notebook cells that have Python code in them do something, hold down the ‘shift’ key and then press the ‘enter’ key (you’ll have to do this to get the YouTube videos to run). To edit a cell (to add answers, for example) you double-click on the cell, add your text, and then enter it by holding down ‘shift’ and pressing ‘enter’
This assignment is due by 11:59 p.m. the day before class, and should be uploaded into the appropriate “Pre-class assignments” dropbox folder. Submission instructions can be found at the end of the notebook.
Imports for the Day#
One of the downsides of notebooks is knowing when things got imported and what modules were important. Trying to get into the habit of including all of the important imports at the top of the notebook is a good way to ensure that you don’t run into issues later on in the notebook. When you restart the notebook, you can run that first cell to get the imports right.
from IPython.display import HTML
from IPython.display import YouTubeVideo
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
1. Reviewing the basics of Pandas#
Pandas is a fundamental tool for doing Data Science work in Python. While we can do this work in straight Python, Pandas makes much of that work easier. We cannot do justice to all of Pandas, as it is a big package, but here we’ll remind ourselves of some of the basics. As you do more data science work, you’ll pick more and more of Pandas as you go along.
What follows should mostly be review. Feel free to reach out and find tutorial pages that might help with reminding you of how Pandas works. Make sure to bookmark any pages or tutorials you find that are particularly useful!
1.1 Pandas Series#
The basic Pandas data structure is called a Series. It is a sequence, not unlike a numpy array, but with an associated set of labels for each value called the index. If you don’t provide the index labels, Pandas will use the regular 0-based index as the label. Again: if you don’t provide index labels, it will use the numeric index as the index label. That will be important later.
You can make a Series using either a python dict, with keys as the indices, or by separately providing the values and indices. You can also updated the index labels or reset the labels to the default. Note however that the reset_index method does not change the Series but returns, not a Series but a DataFrame, where the original index is preserved as a new column.
✅ Review the following example and make sure you understand everything that is happening.
# assumes you have imported Pandas as pd in the cell at the top of this page
series_index = pd.Series([1,2,3,4], index=['one', 'two', 'three', 'four'])
print("\nSeries with indices")
print("Type:", type(series_index))
print(series_index)
series_noindex = pd.Series([5,6,7,8])
print("\nSeries with default indices")
print("Type:", type(series_noindex))
print(series_noindex)
my_dict = { 'nine': 9, 'ten':10, 'eleven':11, 'twelve':12 }
series_dict = pd.Series(my_dict)
print("\nSeries from a dictionary")
print(series_dict)
1.2 Manipulating Series#
Once you have a Pandas Series object, You can access the values in a number of ways:
using the label in [ ], much as you would in a dictionary
using data member “dot” (
.) access, if the label name would constitute a valid Python variable name (can’t start with a digit for example)using numpy array indexing
Without a label (using default indices) you are restricted to using only the last approach.
✅ Review the following mechanisms for accessing data in a Pandas series based on the format and structure of the Series object.
#using label
print(series_index["three"])
#using data member access
print(series_index.three)
#using array index, 0-based
print(series_index[2])
# no labels
print(series_noindex[2])
# series_noindex.2 # can't, 2 isn't a valid Python variable name
Once you have a series object, you can assign/change the values to any of the locations that you can access. Like so:
print("Before:")
print(series_dict)
print("---")
series_dict["eleven"] = 111
series_dict.twelve = 122
print("After:")
print(series_dict)
1.3 Numpy like operations#
Finally, as a reminder, you can do many of the things you learned to do when indexing NumPy arrays with a Pandas Series object as well.
✅ Review the following examples to remind yourself how you can use NumPy-style operations to access Series data in Pandas.
Look at how you can work with ranges of the series elements. The labels are ordered and so the following works:
print(series_index["two":])
You can also apply Boolean masks to a Series:
print(series_dict[series_dict <= 10])
And you can perform operations which return a new series (but don’t modify the existing one):
print(series_dict * 2)
print(series_dict.mean() )
There are many operations you can perform on a Pandas Series object (over 200 last we checked!). You’ll pick up more as you continue to become a Pandas expert.
2 Reviewing the Pandas Dataframe#
A Pandas DataFrame is a 2 dimensional data structure. The easiest way to think of a DataFrame is as a group of Series objects where each Series represents a column in the 2D structure. As with Series you can make them a number of ways but the standard way is to use a dictionary where the keys are the column headers and the values are a list of values under that header.
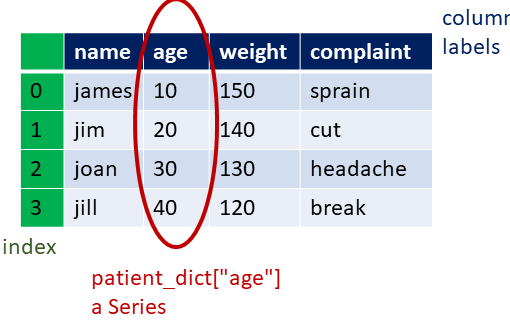
It is always important to know the types in each column as that can affect the kinds of operations you can perform on a column. Listing the .dtypes provides such a list. A type of object is likely (though not necessarily) a string.
An index for the rows is provided by default using 0-based array indexing. The use of [] label indexing returns a Series which is a column with that heading name. The index of the entire DataFrame is used for the returned Series.
✅ Run and review the following code:
patient_dict = {"name":["james","jim","joan","jill"],
"age":[10, 20, 30, 40],
"weight":[150, 140, 130, 120],
"complaint": ["sprain", "cut", "headache", "break"]}
patient_df = pd.DataFrame(patient_dict)
print(type(patient_df))
print(patient_df)
print("\n Column types")
print(patient_df.dtypes)
print("\n age column")
age = patient_df["age"]
print(age)
print(type(age))
2.1 Data Frame indexing#
As we noted above, the index for a DataFrame by default is a 0-based array index. However, we can choose to use a different column as an index for the DataFrame. The .set_index() method allows us to set the index.
An irritating issue is whether the Series being worked on changes. Typically it does not but most methods provide a inplace = True setting to apply the changes to the existing element. Otherwise you must assign the result to preserve it.
If you do not do so, the column being used as an index is no longer available using standard indexing. If you provide drop = False in set_index, the column is preserved in the DataFrame as well as in the index. If you .reset_index() returns to 0-based indexing
To access a row, you can use either .loc or .iloc
.locuses the row index label to access the row (or the 0-based index of none is provided). It returns a Series.ilocuses the 0-based index regardless of whether a label exists. It too returns a Series
Indicies and headers are preserved in the Series indexed from a DataFrame
✅ Take a look at the following and make sure you can follow how the dataframe is being manipulated.
patient_df.set_index("age", inplace=True)
print("\nAge is now the index")
print(patient_df)
# reset to 0-based
patient_df.reset_index(inplace=True)
print("\nBack to 0-based indexing")
print(patient_df)
# keep age as a column
new_df = patient_df.set_index("age", drop=False)
print("\nDon't change the original")
print(patient_df)
print("\nIndex by age, keep the age column")
print(new_df)
2.2 Try it yourself#
Now that you’ve reviewed the many different ways you can create and interact with Pandas dataframes, it’s your turn to dust off the cobwebs and build your own dataframe from scratch!
✅ Try doing the following:
Make a DataFrame to store student grades. The column headers should be:
Name
PID
Total Percent Grade (out of 100)
Final Grade Point (on the 0.0 - 4.0 scale)
Make up some names and values to fill your Dataframe. Include at least 8 students.
Then:
Set the index to be the PID
Print every student in the dataframe who got a 3.0 or greater
# Put your code here (you may wish to create additional cells as you build your DataFrame and test your code)
Follow-up Questions#
Copy and paste the following questions into the appropriate box in the assignment survey include below and answer them there. (Note: You’ll have to fill out the section number and the assignment number and go to the “NEXT” section of the survey to paste in these questions.)
Is there anything involving using Pandas that you’re curious about or are there any specific issues you’ve run into in the past with Pandas that you couldn’t find a solution for?
On a scale of 1-5, with 1 being “not at all confident” and 5 being “extremely confident”, how confident are you in your Pandas skills currently?
Assignment wrap-up#
Hopefully you were able to get through all of that. We’ll be trouble-shooting any issues you had
You must completely fill this out in order to receive credit for the assignment!
from IPython.display import HTML
HTML(
"""
<iframe
src="https://cmse.msu.edu/cmse202-pc-survey"
width="800px"
height="600px"
frameborder="0"
marginheight="0"
marginwidth="0">
Loading...
</iframe>
"""
)
Congratulations, you’re done with your pre-class assignment!#
Now, you just need to submit this assignment by uploading it to the course Desire2Learn web page for the appropriate pre-class submission folder (Don’t forget to add your name in the first cell).
© Copyright 2024, Department of Computational Mathematcs, Science and Engineering at Michigan State University