In-Class Assignment: Linear Regression#
Day 13#
CMSE 202#
✅ Put your name here
#✅ Put your group member names here
#
Goals for today#
After this assignment, you will be able to:
plot a distribution of data
construct and visualize the correlations between different variables in a data set
use
statsmodelsto perform a linear regressioninterpret the quality of the linear fit
perform a linear regression from scratch
Agenda for today’s class:#
Part 0: Revisiting Git#
It’s been a while since we have practiced with git. So,the agenda of this section is to revisit the concepts of Git by creating a new folder inside the cmse202-s24-turnin repository called Day-13 and adding this notebook.
So, for this ICA try:
Navigate to your cmse202-s24-turnin local repository.
Create a new directory called Day-13.
Add the ICA notebook into the new directory.
Commit the changes
Finally, push your changes to Github.
1. Exploring unfamiliar data#
Abalone are a class of marine snails that create a shell of “nacre” of increasing thickness over the course of their lifetime. A very good indication of the age of a particular abalone is the number of “rings” of nacre that have been deposited in the creation of the shell. We are going to look at a data set that is used to estimate the number of rings of a particular abalone shell based on various other abalone characteristics.
On the course supplemental data repository, there are two files you’ll need for this assignment. The first is Dataset.data which contains 4177 individual abalone measurements. The second is Dataset.spec which contains the labels for the 9 columns.
Note a couple of things:
The values in the data file are space separated. You should be able to load this data using Pandas.
The first column is categorical (non-numeric) data. You can ignore it going forward.
The final column, the count of
rings, is the dependent variable that we will use.
✅ Do This: To get started, you’ll need to download the following two files:
https://raw.githubusercontent.com/msu-cmse-courses/cmse202-supplemental-data/main/data/Dataset.data
https://raw.githubusercontent.com/msu-cmse-courses/cmse202-supplemental-data/main/data/Dataset.spec
1.1 Loading and describing the data#
✅ Do This: Using pandas, load the data from the data file. Then, calculate and display the following concerning the rings data of the samples:
the max
the min
the mean
the median
a histogram (using any tool you like) of the distribution of
ringsvalues
There’s more than one way to do this – you should discuss ideas for how to do with with your group!
# put your code here
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import numpy as np
sns.set_context("notebook")
1.2 - Looking at correlations between variables in your data#
Let’s make a correlation matrix of the variables in the abalone dataset and plot it as a heat map.
A pandas DataFrame has a built-in method that can provide a correlation matrix of the variables in the frame. The values show up as a matrix where the rows and columns are the column headers. The value in each cell is the correlation of that pair of values. The correlation values range from -1 to 1.
A correlation of 1 means that the two data elements are perfectly positively correlated. As one goes up, so does the other in exact agreement.
A value of -1 means that as one goes up, the other goes down in exact agreement; this is perfectly negatively correlated.
A correlation value of 0 means there is no correlation.
Anything in between -1 and 1 gives the degree to which there is a positive or negative correlation between two variables. The diagonal of the matrix is all ones since that the correlation of the column with itself.
What is the pandas the method for producing a correlation matrix for a DataFrame?
✅ Do This: Calculate and display the correlation matrix associated with your data. NOTE: Depending on your numpy version, this step might initially give you an error. If this is the case, remove the sex column from the dataframe.
# put your code here
✅ Questions: What do you notice? Can you find variables that correlate strongly with the number of rings? What might make finding these variables this easier?
✎ Do this - Erase this and put your answer here.
The tools seaborn is useful for visualization. You can display a heatmap, a color for each cell, of a correlation matrix. It gives a visual clue as to what data elements are correlated.
✅ Do this: Generate a heatmap for the correlation matrix from above and plot it onto the given figure and axis.
fig, ax = plt.subplots(1,1, figsize = (10,10) )
# put your code here
✅ Questions: What do you notice? Can you find variables that correlate strongly with the number of rings and do the agree with what you found by examining the correlation matrix? What makes this a better representation of your data than simply the matrix above?
✎ Do this - Erase this and put your answer here.
2. Linear Regression#
Looking at our heatmap, select the independent variable that has the best correlation with the dependent variable rings.
✅ Do this: Write in the cell below what variable you will work with below.
✎ Do this - Erase this and put your answer here.
2.1 Perform the regression using statsmodels#
Having selected an independent variable, let us do a linear regression using your selected variable (let’s just call it x) and the rings variable (let’s just call that y). Using what you reviewed in your pre-class assignment, we’ll used statsmodels for this.
✅ Do this: Using statsmodels, perform a linear regression to predict the number of rings using the indepdent variable you selected. Print the slope and the intercept for your model.
Look to the pre-class assignment for some hints and check in with your group.
# put your code here
2.2 Print statistics#
While this model has provided the slope and intercept for the fit, it has not suggested how well the model fits our data. Luckily, the results produced by the fit() method can provide a summary.
✅ Do this: Print the statistics associated with your fit. Comment below that on how well the fit is for the data.
# put your code here
✅ Do this: Comment on the fit of your model. What are you using to judge the fit?
✎ Do this - Erase this and put your answer here.
2.3 Visualizaton#
Mathematically, any data can be fit to a line. Whether a line is a good model to use to fit that data depends on a number of issues. Once of the more famous examples of data being fit to a line where that data has precisely the same fit, but wildly different data is Anscombe’s quartet. The main figure is reproduced below:
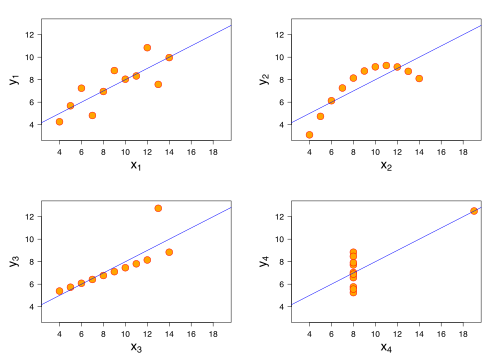
You can see that each data set is different, but the mathematical model that fits each of these data sets is the same! You must be careful that your data do not violate one or more of the underlying assumptions of linear fitting. This is one reason it is incredibly important to visualize your data and the model that fits it.
✅ Question: For the four plots above, which would you find believable? That is, which ones are reasonable fits to the data and why?
✎ Do this - Erase this and put your answer here.
✅ Do this: Plot the scatter plot of your independent and dependent data and also plot the line predicted by the regression.
# put your code here
✅ Do this: How well does your model fit your data? Look back at the measure you used to judge the fit initially, what more information do you gain from plotting the data and the fit? Would you say that you had a good model of your data? What might make your model better?
✎ Do this - Erase this and put your answer here.
Thinking carefully about what model we use to fit data is important, as is how we judge the quality of our models and the fits we come up with. We’ll have more opportunities to discuss this in future assignments as well.
3. Are we justified in using linear regression?#
One of the critical assumptions of linear regression is that of “constant variance”. This means that the different values of the dependent variable have the same variance in their errors, regardless of the value of the independent variable. This is typically checked using a residual plot, which is available using plot_regress_exog. If the distribution of residuals (a proxy for the errors) is evenly distributed, we can feel more confident that we were justfied is using linear regression.
✅ Do this: Use plot_regress_exog to investigate the distribution of residuals in your model fit. Make sure to create a large enough figure so that everything is easily visible
# put your code here
fig = plt.figure(figsize= ??? )
✅ Questions: Does it appear you were justfied in using linear regression? Why or why not? If it helps, you might look back at the same plot you made for the noisy data in the pre-class assignment.
✎ Do this - Erase this and put your answer here.
✅ Questions: You might also be able to tell if your linear model overpredicts or underpredicts the number of rings with this model for certain values of your independent variable. Can you? If so, does it over/under-predict?
✎ Do this - Erase this and put your answer here.
4. Building the fit from scratch#
The statsmodels library is quite powerful and has a number of tools that we will use to fit data. But in the simplest fit it can do, a linear model of one variable, what is the library doing? You will perform the calculations yourself below to try construct the same fit to your data.
4.1 Performing a Least Squares fit#
Let’s do some of that work ourselves to see if we can reproduce those results. We are going do the math for linear regression ourselves and see if our math agrees with the tools we used above. Below is the math. We’ll use the same independent and dependent variables that you chose above.
Let’s assume that the symbols \(\bar{x}\) and \(\bar{y}\) represent the means of those arrays and that n is the number of elements.
Here’s the calculation for the slope for a single variable linear model: $\( slope = \frac {\sum_{i=1}^{n}{(x_i - \bar{x}) * (y_i - \bar{y}) } } {\sum_{i=1}^{n}{(x_i - \bar{x})^2}}\)$
Here’s the calculation for the intercept for a single variable linear model: $\( intercept = \bar{y} - slope*\bar{x} \)$
✅ Do this: Using the same independent variable and the same dependent variable as above, calculate the slope and intercept of the best fit least squares using the formula provided. Print the slope and the intercept.
# put your code here
✅ Question: How well do your slope and intercept agree with the results from statsmodels?
✎ Do this - Erase this and put your answer here.
✅ Do this: Plot the same scatter plot for your data you used above and plot the new regression line through that data using your calculated slope and intercept.
# put your code here
4.2 Coefficient of Determination and Mean-Squared Error#
We will now calculated the coefficient of determination (\(R^2\)) and the mean-squared error (MSE). These results are also produced by statsmodels in its summary statistics.
The coefficient of determination calculations are as follows:
Total sum of squares is: $\( tsum = \sum_{i=1}^{n}{(y_i - \bar{y})^{2}} \)$
The sum of the squares of the residuals (also called the residual sum of squares) is: $\( residual = \sum_{i=1}^{n}{(y_i - y_{predicted})}^{2} \)$
Mean-squared error is just $\( MSE = \frac{1}{n} * residual\)\( or \)\( MSE = \frac{1}{n}\sum_{i=1}^{n}{(y_i - y_{predicted})}^{2} \)$
The coefficient of determination (\(R^2\)) is: $\( cod = R^2 = 1 - \frac{residual}{tsum} \)$
✅ Do this: Using the same data you used above, develop a new array y_predict based on your calculated slope and intercept. Provide the coefficient of determination and mean-squared error of your calculated regression model.
# put your code here
✅ Question: How well do your results agree with the results from statsmodels?
✎ Do this - Erase this and put your answer here.
Congratulations, you’re done with your in-class assignment!#
Now, you just need to submit this assignment by uploading it to the course Desire2Learn web page for today’s submission folder (Don’t forget to add your names in the first cell).
© Copyright 2024, Department of Computational Mathematics, Science and Engineering at Michigan State University