Jupyter Notebook#
Lecture 30: Multi-Layer Neural Nets#
# Everyone's favorite standard imports
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import time
from sklearn.model_selection import train_test_split
Today we are going to build some basic neural nets using pytorch.
This lecture makes use of many helpful available tutorials, including those listed below:
Get up and running#
Your first job is to get pytorch running on your machine.
If you’re on DECS EGR jupyterhub……#
This year, it would seem that all the necessary requirements are already installed. If you are having issues, please talk to your instructor first! DO NOT try to run pip install torch as this will cause major issues with the amount of space you have on JupyterHub.
If you’re on a local machine……#
Your first job is to install pytorch.
pip install torch
We will also be using some example data sets found in the following package.
pip install torchvision
Either way…..#
If all goes well, the imports below should work.
import torch
from torch import nn
import torch.optim as optim
# import torch.trainloader
import torch
import numpy as np
from torch.utils.data import TensorDataset, DataLoader
Our first job is to build our chosen architecture. One of the simplest ways to do this is with the nn.Sequential class. All we need to do is to pass information about what we want to do at each step. The following code builds a neural network with:
Input of two variables \((X_1,X_2)\), so \(p=2\)
A first hidden layer with 5 units, where we take linear combinations of the inputs and then use the ReLU activation function.
A second hidden layer with 3 units, this time using the Sigmoid activation function
A final output layer
# Hyperparameters for our network
input_size = 2
hidden_sizes = [5,3]
output_size = 1
# Build a feed-forward network
model = nn.Sequential(nn.Linear(input_size, hidden_sizes[0]),
nn.ReLU(),
nn.Linear(hidden_sizes[0], hidden_sizes[1]),
nn.Sigmoid(),
nn.Linear(hidden_sizes[1], output_size))
print(model)
Note at this point that we haven’t trained anything or used data in any way. This is only the setup. This is like when we were doing linear regression, and we have linreg = LinearRegression() but we hadn’t done linreg.fit(X,y) yet.
✅ Do this: Write code to build an architecture with the following specifications:
\(p=20\) input variables
Three hidden layers, with 10, 5, and 3 units respectively.
Use the ReLU activation function at every step.
Note you’re not training the model, just setting up the architecture.
# Your code here
Building the simple architecture from last class#

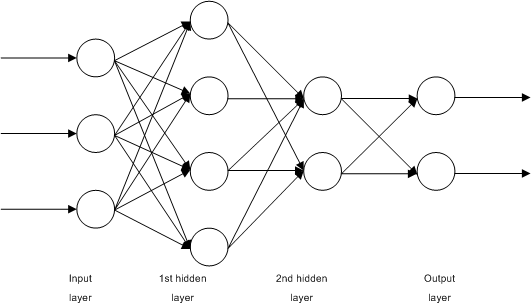
✅ Do this: Build the model for the example we used in the last class, with the picture included above. This model had two input variables, three hidden units in a single layer, and a single output. Use ReLU for your activation function. Save your model as mySecondNN.
# Your code here.
Here is our very simple data set to use. It’s similar to the data set from last time, just with way more data points.
data = np.loadtxt('../../DataSets/DL-toy-data-bigger.csv')
X = data[:,:2]
y = data[:,2]
plt.scatter(X[:,0],X[:,1], c= y)
plt.colorbar()
plt.show()
data.shape
In order to make torch play nice with this data set, I’m going to put it in a custom class. Don’t worry too much about this, it’s just to make some things easier later.
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
DL_toy_torch = CustomDataset(X, y)
I’m going to build a train/test split before getting into the pytorch framework. I need to convert my input data to pytorch’s fancy DataLoader class.
import torch
from torch.utils.data import random_split
# Split the dataset into 80% train, 20% test
# Unlike sklearn, torch wants a length of the training size rather than the percentage
train_size = int(0.8 * len(DL_toy_torch))
test_size = len(data) - train_size
train_dataset, test_dataset = random_split(DL_toy_torch, [train_size, test_size])
# Create DataLoaders for the train and test sets
trainloader = torch.utils.data.DataLoader(train_dataset, batch_size=64)
testloader = torch.utils.data.DataLoader(test_dataset, batch_size=64)
Essentially, the trainloader and testloader are now storing our data sets. The batch_size input is to allow for only loading in a subset of our data at a time. For our silly little data set, this doesn’t particularly matter. However, for real data sets with gigabytes of data, the batch size makes it so that we don’t overload the memory of the computer trying to read in the whole data set at once.
Below, we can see that if we iterate over trainloader, we are handed 64 data points at a time, with their X and y information separated
for data_X, data_y in trainloader:
print(f"data_X is a subset of X with shape {data_X.shape}")
print(f"data_X: ")
print(data_X[:10, :])
print("\n")
print(f"data_y is the matching labels of y with shape {data_y.shape}")
print(f"data_y: ")
print(data_y[:10])
print('---')
break #<---- Comment to show a the entire output of the iteration
Now for the actual training of the model. We are not covering the inner workings of the training in class, so for the purposes of today you don’t need to worry much about the specifics here. However, the basic idea is that epochs gives us the number of times we’re willing to update our coefficients to see if we’re improving. “Improving” is measured by the loss function, in this case chosen to be nn.MSELoss which uses mean squared error.
The code below will run over multiple epochs, and store the training loss at each step.
%time
LossList = []
criterion = nn.MSELoss()# Optimizers require the parameters to optimize and a learning rate
optimizer = optim.SGD(mySecondNN.parameters(), lr=0.003)
epochs = 300
for e in range(epochs):
running_loss = 0
for data, target in trainloader:
data = data.float()
target = target.float()
# Training pass
optimizer.zero_grad()
# Forward pass
output = mySecondNN(data) #<--- note this line is using the model you set up at the beginning of this section
# Calculating the loss
# output = output.float()
# target = target.float()
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
else:
LossList.append(running_loss/len(trainloader))
# print(f"Training loss: {running_loss/len(trainloader)}")
plt.plot(LossList)
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.show()
Note that the training loss appears to be improving over time. Now we can then predict using our trained model on our test set to see how well we are really doing. The only reason this code is as complicated as it is is the batch loader, otherwise the main work is done with the criterion(prediction, target) command.
Out_predict = []
Out_target = []
for data_X, data_y in testloader:
predict = mySecondNN(data_X.float())
Out_predict.append(predict)
y_test_tensor = data_y.float()
Out_target.append(y_test_tensor)
all_predictions = torch.cat(Out_predict)
all_targets = torch.cat(Out_target)
criterion(all_predictions,all_targets)
Of course, this data set is very tiny, with not much to be done in terms of training, so lets go look at a bigger data set.
MNIST data set#
Now that we know the basics, we can build a neural net like discussed in class on the MNIST data set. The first time you run the commands below, it will save the MNIST data set into a folder called MNIST in the same place you’re running this jupyter notebook. After that, it will just reload the data from that folder as long as it hasn’t moved.
from torchvision import transforms, datasets
train = datasets.MNIST('', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor()
]))
test = datasets.MNIST('', train=False, download=True,
transform=transforms.Compose([
transforms.ToTensor()
]))
print('---Train---\n')
print(train)
print('\n---Test---\n')
print(test)
As before, we are loading in our data set in batches to keep from crashing your memory.
trainloader = torch.utils.data.DataLoader(train, batch_size=10, shuffle=True)
testloader = torch.utils.data.DataLoader(test, batch_size=10, shuffle=False)
Let’s take a look at our data. The following code lets me spit out the first batch of data.
for images, labels in trainloader:
print(images)
print(labels)
break
Note that images is a tensor of input data points from the first batch, while labels is a tensor of the labels.
labels
This data happens to be from images of digits, so we can visualize each input data point and its label as follows. Mess around with the i value to see different data points in this batch.
i = 0 #<---- this number can be from 0 to 9, and will show different data points
# Notice that the index i is not the same as the label of the integer in the pic.
X = images[i]
y = labels[i].item()
plt.imshow(X.view(28,28))
plt.title('This is a ' + str(y))
For our data set, we will simply flatten each image into a vector to pass into the neural network. That means that because each image is \(28 \times 28\) pixels, we will end up with a flattened data point of size 784. The code below is taking each image from the batch, flattening it to a vector, and returning the 10 data points in the batch as below
images_flat = images.view(images.shape[0], -1)
print(images_flat)
print(images_flat.shape)
Ok, so now we can actually train our model on MNIST!
✅ Do this: For the code below, sketch the diagram for the model we’ve built.
input_size = 784
hidden_sizes = [128, 64]
output_size = 10
model = nn.Sequential(nn.Linear(input_size, hidden_sizes[0]),
nn.ReLU(),
nn.Linear(hidden_sizes[0], hidden_sizes[1]),
nn.ReLU(),
nn.Linear(hidden_sizes[1], output_size),
nn.LogSoftmax(dim=1))
print(model)
Now you can run the code below to train your model!
Warning: This code can be pretty slow. On my desktop, it took about 3 minutes. You can try things like increasing the number of epochs, but note that this will also increase the running time.
%%time
# Define the loss
criterion = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.003)
epochs = 5
for e in range(epochs):
running_loss = 0
for images, labels in trainloader:
# Flatten MNIST images into a 784 long vector
images = images.view(images.shape[0], -1)
# Training pass
optimizer.zero_grad()
output = model(images)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
else:
print(f"Training loss: {running_loss/len(trainloader)}")
We can then look at what sorts of predictions we have for new data points.
# This function is just for drawing. As with the rest of this
# tutorial, the code is adapted heavily from
# https://github.com/amitrajitbose/handwritten-digit-recognition
def view_classify(img, ps):
''' Function for viewing an image and it's predicted classes.
'''
ps = ps.data.numpy().squeeze()
fig, (ax1, ax2) = plt.subplots(figsize=(6,9), ncols=2)
ax1.imshow(img.resize_(1, 28, 28).numpy().squeeze())
ax1.axis('off')
ax2.barh(np.arange(10), ps)
ax2.set_aspect(0.1)
ax2.set_yticks(np.arange(10))
ax2.set_yticklabels(np.arange(10))
ax2.set_title('Class Probability')
ax2.set_xlim(0, 1.1)
plt.tight_layout()
The code below will show the image, and the probabilities for each class label. The actual prediction comes from the label with the highest probability.
i = 4 #<--- Mess with this number to see different data points and their predictions
images, labels = next(iter(testloader))
img = images[i].view(1, 784)
with torch.no_grad():
logps = model(img)
ps = torch.exp(logps)
probab = list(ps.numpy()[0])
print("Predicted Digit =", probab.index(max(probab)))
view_classify(img.view(1, 28, 28), ps)
# plt.savefig('MNIST-ExamplePrediction.png',bbox_inches = 'tight')
The code below will show the count of correct predictions.
correct_count, all_count = 0, 0
for images,labels in testloader:
for i in range(len(labels)):
img = images[i].view(1, 784)
# Turn off gradients to speed up this part
with torch.no_grad():
logps = model(img)
# Output of the network are log-probabilities,
# need to take exponential for probabilities
ps = torch.exp(logps)
probab = list(ps.numpy()[0])
pred_label = probab.index(max(probab))
true_label = labels.numpy()[i]
if(true_label == pred_label):
correct_count += 1
all_count += 1
print("Number Of Images Tested =", all_count)
print("\nModel Accuracy =", (correct_count/all_count))
Still have time?#

Try building a neural net to predict labels on the FashionMNIST data set.
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
# Download training data.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Download test data.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
The labels are stored as digits, but below is the map from the documentation.
labels_map = {0: 'T-shirt/top', 1: 'Trouser', 2: 'Pullover', 3: 'Dress', 4: 'Coat', 5: 'Sandal', 6: 'Shirt', 7: 'Sneaker', 8: 'Bag', 9: 'Ankle boot'}
This code will show you a random collection of sample images.
# This code will show you a random collection of sample images.
fig, ax = plt.subplots(nrows=5, ncols=5, figsize = (20,10))
for row in ax:
for col in row:
entry = np.random.randint(100)
col.imshow(training_data.data[entry])
col.axis('off')
col.set_title(labels_map[training_data.targets[entry].item()])
# plt.savefig('FashionMNIST-Examples.png', bbox_inches = 'tight')
# Your code here
Congratulations, we’re done!#
Written by Dr. Liz Munch, Michigan State University

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.