CMSE 495
This is the webpage for CMSE495 Data Science Capstone Course (Spring 2022)
Creating a project GIT repository
![]()
BACKGROUND
In this milestone project you will create a git repository and share it with your classmates and instructors. This repository will be used for the remainder of the course to turn in all project related documents. By the end of the semester your repository will have a structure similar to the following:
ProjectName/
.gitignore
docs/
package_name/
module1.html
module2.html
images/
image1.jpg
environments.yml
Examples/
datafile1.csv
datafile2.tiff
datafile3.xls
Figures/
Generate_Figure1.ipynb
Generate_Figure2.ipynb
Generate_Figure3.ipynb
LICENSE.txt
makefile
Reports/
Meeting_Minutes.md
Team_Charter.md
Project_proposal.ipynb
Closed_loop_Report.ipynb
package_name/
__init__.py
module1.py
module2.py
test/
__init__.py
test_module1.py
test_module2.py
README.md
setup.py
Final_Report.ipynb
Examples
Here is an example projects you can download from a different course with a similar structure. Note these may have had slightly different expectation and assignment goals relative to your project but are still good representation of the types of projects that would be acceptable for this course. Projects shared with permission by former students:
- F19 Neutrino Winds - By Brian Nevins
- F19 Enhanced sampling Methods - By Nicole Roussey
- F19 Visualization of the Transport of Small Molecules on Peptides - By Xie Yan
Even more projects (may require logging into MSU GitLab to access:
- F19 Lattice QCD Data Analysis - By Matthew Zeilbeck
- F19 A Tool for Applying Postseismic Corrections to Geodetic Data - By Connor Drooff
- F19 OMR Extracter - By Babak Safae
INSTRUCTIONS
For this milestone we only need to set up the basic structure with the following:
ProjectName/
.gitignore
LICENSE.txt
makefile
README.md
Team/
Team_Charter.md
Here is a description of each of these:
ProjectName- The top level folder is the shortname of your team. Give your project a short and memorable name. An ideal name should be descriptive and have meaning to people who may be interested in using your software. A poor name only has meaning to your team. For example, DO NOT USE CMSE495 NOR YOUR NAME in the the name. Instead try to pick a name that relates to your project or what you think your project will do. Although we can change the name later it is much easier if we pick a good name to start.README.md- This is a description of your git repository written in Markdown. For now this file can just contain your team names..gitignore- There are a lot of files that are inappropriate to include in a git repository (more information below) the “Git Ignore” file helps by telling Git that you never want to use these files. There are plenty of examples for good.gitignorefiles for Python projects on the Internet. Try to include one that makes sense (you can update it as the semester goes on).LICENSE- Use this file to describe your license (See section below).makefile- We will be using Make to help other people and run the teams project code. For now just copy and paste the text in the section below.
HINT: Many of you may find this git template helpful.
If you need help figuring out how to set up your git repository there are a ton of tutorials online. For example here is a good one:
If you continue to need help go see your instructors.
The following video are instructions specifically for how to use the MSU Gitlab. We will be using the MSU gitlab for all projects because it allows us to best maintain file permissions:
Some of you may get some sort of “Authentication” error when trying to use git on a windows machine (esspecially if you have your computer already set up to use github). If that is the case, the following video may help you set up an SSH key on your windows machine.
As you update and change the files in your repository you will need to push those changes to gitlab. The following instructions walk you though this process:
Adding in a team Charter
The team charter is a contract between all members of the capstone team. it is designed to lay out the goals of the team and help avoid future problems. All members of the team must “Sign off” on the team charger and agree to adhere to the guidelines specified. Here are some things to include in the charter:
- Team Name
- Team Objectives
- Team Scope
- Background, Boundaries
- Team Strategy
- Plans, Metrics
- Ground Rules
- Membership, Meetings, Reports
Here is some more information about putting together a team chater
What not to include (building a .gitignore file)
First thing we want to teach is is that not everything should go into a git repository. i.e. we do not want to bloat our repository with unwanted files. The git repository works best with Text files that represent “source” code and not compiled or generated code. Here are some basic guidelines of what not to include:
.ipynb_checkpoint- These folders are generated when you run jupyter notebooks. They are “temporary” compiled folders that will change each time you run your notebook and should not be included in your repository.__pychache__- Similar to .ipynb_checkpoint folders these folders are often generated when running python scripts and should not be included in your repository.- Other “Temporary” files - Temporary files are generated by all types of software and often start with a special characters such as the dot (.) or the tilde (~). For example many text editors generate temporary files to save a document in case of a program crash. Do not include temporary files in your repository.
- Compiled Code - Programs such as C and FORTRAN must compile their code to an executable in order to run on your computer. These compiled codes are not editable and should be left out of your repository. Instead it is better to include instructions for compiling the source code as part of your repository.
- Program Output - Do not include any program output in your repository (unless for very specific reasons such as documentation, testing, or figures in your final report). Assume that any output that can be generated by the source code should not be included with the source code (it is redundant).
A good rule of thumb is that if you did not generate the file and/or do not know what it is you probably do NOT want to include it in your repository.
WARNING do not blindly add all files to your repository with the * (star) syntax. This is bad practice. For example do NOT do the following:
git add *
Other files to avoid
In addition to the above files it is good to avoid any type of “Binary” file (with a few exceptions). As stated early, git works best with text files so it can easily track changes. Some example binary files to avoid include:
- Large Data files Although it is good to include a few example inputs to your software, avoid using entire datasets. It is best to store these files someplace else.
- Non-Text formats such as Word, Excel or PowerPoint documents should be avoided. These tend to change each time they are opened even if the core text does not change. it is better to use an alternative text example.
Note: one exception to the above rules are image files (ex jpg or png) that are used to help markdown or in the documentation. It is typically okay to include these since they tend to get included only once and do not change much as the project evolves.
The .gitignore (typically read “dot git ignore”) is a text file that contains a list of regular expressions (we will learn more about these later) that specify names of files we do not want to include in a git repository.
.gitignore file
The .gitignore (read “dot git ignore”) file is used to help keep unwanted files out of your project. Each line .gitignore file are filenames you want git to ignore. For example, based on what we said above, a good place to start on your .gitignore file would be the following two lines:
.ipynbcheckpoint
__pychache__
What should go into a .gitignore depends a lot on the type of project. However, you don’t need to invent these from scratch. For example, you could just copy the .gitignore file from the course repository or find one on the internet.
Licensing file
As authors of software it is important to let people know how they can use our software. The following article is a great resource for learning the types of terminology and logic used when talking about software License.
-
https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1002598
-
https://creativecommons.org/licenses/

Include a ./LICENSE test file in your top directory. Select which license to use using the following website:
Copy and paste your chosen license file into a file named ./LICENSE
The following articles are a great resource for learning the types of terminology and logic used when talking about software License.
- https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1002598
- https://choosealicense.com/
- https://creativecommons.org/licenses/
Make sure you talk to your instructors to know what type of license is appropriate for your project given. What license you use may also depend on the NDA and IP agreement made with you and the sponsor.
Include a ./LICENSE.txt test file in your top directory. Select which license to use using the following website.
Makefile
“Make” is a common Linux command that can help organize command line programs. The idea is that you can “make” some files by running commands on other files. Make works by reading in a file called a makefile. Makefiles are fairly simple in concept but are an entire programming language so can get very advanced. At its simplest level a makefile consists of rules in the following format:
target : prerequisite_file1 prerequisite_file2 prequiste_file3 ...
#Bash build command(s) to make the target file from the prerequisite files
Makefiles can be thought of as Directed Acyclic Graphs (DAGs). For example the makefile found in this file can be visualized as the following dependency graph.
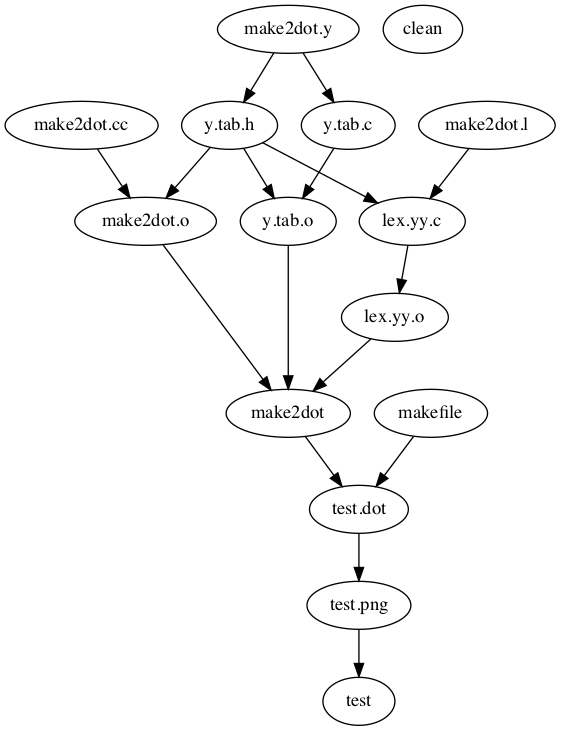
The following is a very simple makefile template you can use in your project. This file has very few dependencies and is just a way to use make to keep track of the utilities we are using in this course:
MODULENAME = YOUR_PACKAGE_NAME
help:
@echo ""
@echo "Welcome to my project!!!"
@echo "To get started create an environment using:"
@echo " make init"
@echo " conda activate ./envs"
@echo ""
@echo "To generate project documentation use:"
@echo " make docs"
@echo ""
@echo "To Lint the project use:"
@echo " make lint"
@echo ""
@echo "To run pydocstyle on the project use:"
@echo " make doclint"
@echo ""
@echo "To run unit tests use:"
@echo " make test"
@echo ""
init:
conda env create --prefix ./envs --file environment.yml
docs:
pdoc3 --force --html --output-dir ./docs $(MODULENAME)
lint:
pylint $(MODULENAME)
UML:
pyreverse -ASmy -o png $(MODULENAME)
doclint:
pydocstyle $(MODULENAME)
test:
pytest -v $(MODULENAME)
.PHONY: init docs lint UML test
Copy the makefile file in the class directory into your project directory, change the YOUR_PACKAGE_NAME name and add/commit the file to your repository. Note some projects will use this makefile extensively while others may not (It will depend on the project).
NOTE: Makefiles formats require tabs instead of spaces so double check before committing. Modify the file as appropriate.
Avoid Spaces in file names
When you name all of the files and folders inside of a repository, it is important that your names DO NOT include spaces. Although all modern computer’s have ways to accept names with spaces do not use them. Instead use underscores (_) or CamleCase (No spaces and capital letters at the beginning of each word in the name). Avoiding spaces in your names will Alaways save time in the long run.
Always Use Relative Paths
In your code there are two basic ways to determine the location of a folder inside your computer; Relative Paths and Absolute Paths. A relative path is a path starting from your current directory and an absolute path is is a path starting from your computer’s “root” directory.
- Relative paths typically start with a single dot (.), representing the currecnt directory, or two double dots (..) representing the current directories parent folder.
- Absolute paths typically start at the global root directory (/) on a Linux or Mac machine or with a drive label (ex C:) on a windows machine.
ALWAYS use relative paths in your git repository. This ensures that others will be able to use your software if they download it onto their computer. For example:
Good: ./data/ or ../data/ is a relative path to a child directory or sibling directory called data.
Bad (not acceptable): C:/research/data or /mnt/home/data are absolute paths to a data directory
Jupyter notebook files in git repositories
Turns out that Jupyter notebook files and git repositories work very poorly together. Jupyter notebook files are a unique combination of source and program generated information. So, everytime you run a jupyter file it can add output cells which make git think you you changed something important. In many cases it is just a few numbers or some output text. When you run the git status command it always looks like jupyter notebook files have changed even when they have not changed.
A good rule of thumb is to clear all of the output files before committing any changes to jupyter notebook files.
- Open the jupyter notebook file
- Select “Reset Kernel and clear output” from the menu
- Save the notebook file.
- Do your “git add” and “git commit” commands
The following video goes though why we have to treat jupyter notebooks this way:
Turning in your GIT repository
In order to turn in your GIT repository you just need to give the instructors and classmates the permissions to clone the repository and provide the full git command. Please use the following form to submit this information.
Or if you prefer, you can use the Direct Link
Congratulations, you are done!
Your instructor can download your git report using the link you provided in the above Google form.
Written by Dr. Dirk Colbry, Michigan State University

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.