1. Quiz Example Navigating the HPCC¶

This question is designed to test your general understanding of how to navigate in Linux/BASH on the HPCC. Complete the following instructions and answer each of the provided questions.
The following are four example quiz questions and are intended for you to use to get practice for your quizzes. These questions come form the Fall 2018 CMSE401 midterm. Each one was intended to take about 20 minutes for students to complete. Your instructor plans to make the quizzes to be formated similar to one of these four problems.
After all of your questions have been answer (or if you run out of time instructors will enable you to download the quiz from the course D2L website.
Download the Quiz and get started. The quiz is designed to take approximately 20 minutes to complete (you will be given 30 Minutes).
The following instructions will be included at the top of your quiz. Make sure you read the instructions. They are included here to save you some time.
This is an open Internet quiz. Feel free to use anything on the Internet with one important exception...
- DO NOT communicate live with other people during the quiz (either verbally or on-line). The goal here is to find answers to problems as you would in the real world.
You will be given 20 minutes to complete this quiz. Use your time wisely.
HINTS:
- Neatness and grammar is important. We will ignore all notes or code we can not read or understand.
- Read the entire quiz from beginning to end before starting. Not all questions are equal in points vs. time so plan your time accordingly.
- Some of the information provided my be a distraction. Do not assume you need to understand everything written to answer the questions.
- Spaces for answers are provided. Delete the prompting text such as "Put your answer to the above question here" and replace it with your answer. Do not leave the prompting text with your answer.
- Do not assume that the answer must be in the same format of the cell provided. Feel free to change the cell formatting (e.g., markdown to code, and vice versa) or add additional cells as needed to provide your answer.
- When a question asks for an answer "in your own words" it is still okay to search the Internet for the answer as a reminder. However, we would like you to do more than cut and paste. Make the answer your own.
- If you get stuck, try not to leave an answer blank. It is better to include some notes or stub functions so we have an idea about your thinking process so we can give you partial credit.
- Always provid links to any references you find helpful.
- Feel free to delete the provided check marks (✅) as a way to keep track of which questions you have successfully completed.
Honor Code
I, agree to neither give nor receive any help on this quiz from other people. I also understand that providing answers to questions on this quiz to other students is also an academic misconduct violation as is live communication or receiving answers to questions on this quiz from other people. It is important to me to be a person of integrity and that means that ALL ANSWERS on this quiz are my answers.
✅ DO THIS: Include your name in the line below to acknowledge the above statement:
Put your name here.
This question is designed to test your general understanding of how to navigate in Linux/BASH on the HPCC. Complete the following instructions and answer each of the provided questions.
For the first step, log into the HPCC and pick a development node (doesn't matter which one). Add the following directory to front of your PATH:
/mnt/scratch/colbrydi/exam1✅ Question 1.a: What command did you use to add the directory to the beginning of your existing path? HINT Copy and Paste your answer after logging out and back in to check your syntax and make sure it works.
In the directory you just added to your path is a program called omp-hello. This is a fairly simple program (feel free to review the source code provided in the same directory). Run the code
✅ Question 1.b:: What development node are you on and how many threads did the program use?
Put the answer to the above question here
Write (or modify) a submission script to run the omp-hello program on the HPCC. Have the script run on a single node with 10 Cores for 1 minute and 1gb of RAM.
HINT you will probably need to include the PATH command from Step 2.a in your submission script so your job will know where to find the command.
✅ Question 1.c: Copy and paste the contents of your working submission script here.
The SLURM Scheduler has the ability to send emails when a job starts, stops and/or has an error. Modify your submission script to email the instructor (colbrydi@msu.edu) when the job starts. HINT look at the man page for the sbatch command.
Submit your submission script so that the instructor will get at least one automated email. Please don't SPAM your instructor too much.
✅ Question 1.d: What lines did you add to your submission script to email the instructor.
Using the vim editor, create a file called .plan in your home directory (note the first character is a dot in the filename). In that file write one to two sentences to share with your classmates. This can be a your life philosophy, a joke, a URL to your homepage, or anything you are willing to share about yourself.
Make the .plan file publicly readable and ensure that the .plan file is publicly readable by checking its properties string.
✅ Question 1.e: What is your .plan file's ten (10) character properties string?
For this question, assume you have just joined a lab under the guidence of Prof A who has asked you to benchmark a FORTRAN program called givemeana (aka "give me an A"). NOTE: the program givemeana is not real program. It is only used here as a way for me to ask you exam questions without you getting distracted trying to find answers using Google. Please answer the following questions as if givemeana is real.
Question 2.a: Name three different commands you could type in the BASH terminal to discover if givemeana is installed on the HPCC. Provide answers that search using different information in the system and not different commands that give exactly the same results because they search the same data.
Assume that you have found the givemeana binary executable and it is located in a folder that is inside your PATH environment variable (maybe it was already in your path, or maybe you loaded a module or maybe you added it to your PATH yourself). When you type givemeana the program outputs the following to the screen:
>givemeana
Usage: givemeana <size> <options>
<size> size of nxn simulation grid
-t number of simulation steps (default 10)
-c number of omp treads (default 1)
-h help (this message)
>
Given the above, answer the following questions:
Question 2.b: The following simple BASH loop is trying to conduct a scaling study from 2 to 10 CPUs. However, the {2...10} syntax is wrong. Modify the code to correctly iterate from 2 to 10 CPUs.
#!/bin/bash
for n in {2...10}
do
time givemeana 10000 -c $n -t 1000 > $n.out
done
Question 2.c: Given that givemeana is not a real program and therefore will cause a "file not found" error if you try to run it. How did you test your answer code in Question 2.b to verify it is correct?
Put your answer to the above question here.
Question 2.d: The above script will create some files. What are the files names and what would be stored in those files. HINT This is a tricky question. Run a test and make sure you understand how the time command works.
Put your answer to the above question here
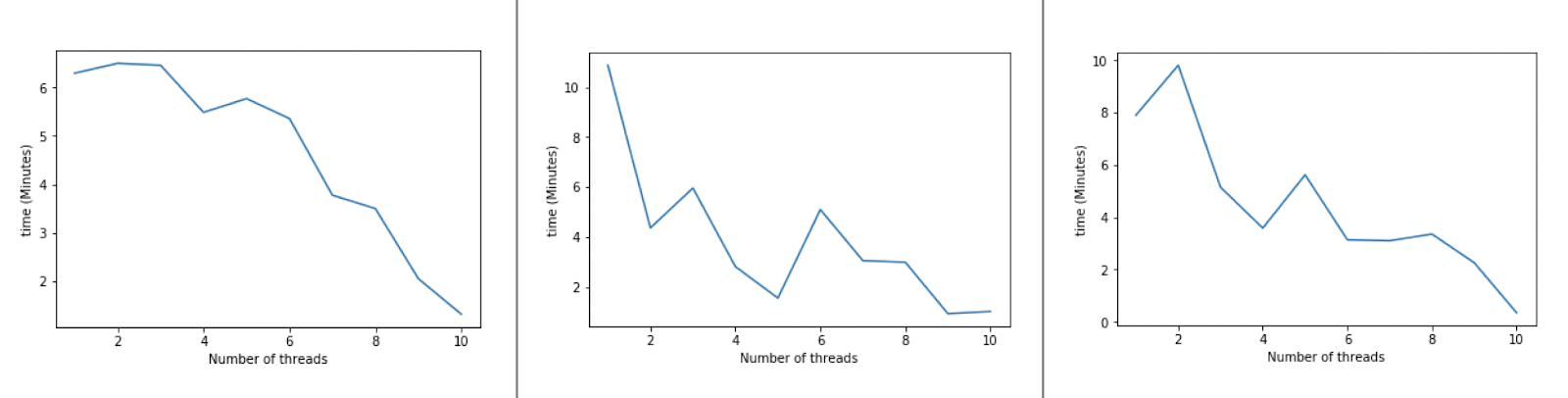
The program was tested three times and the timing results were plotted as follows:
Question 2.e: The writer of givemeana ensures you that the amount of computation per run is the same (i.e. there is no random component to the calculation). Describe some other possible sources of the variation in the data seen above. Describe at least two things you could do to improve the methodology of this scaling study and provide more consistent results.
Put your answer to the above question here.
Computational Fluid Dynamics (CFD) uses numerical analysis to analyze and solve problems that involve fluid flows such as air moving over an airplane wing. A common CFD program is called fluent (made by ANSYS) which is installed one the HPC.
Fluent is a simulation program that divides computational work by splitting up the simulated environment into discrete blocks (also called mesh elements). At each timestep, each element only models the fluid flow within it's boundaries by solving a set of Partial Differential Equation. When all blocks are done they communicate with each other by exchanging information about the fluid that crossed the boundaries during the time step. Some very high level psudo-code is as follows:
#Run simulation over all timesteps
for t in timesteps
#Have each meshelment evaluate it's change over the current time step.
for e in meshelements
e = solvemodel(e)
#Exchange information that crosses the boundaries.
for e in meshelements
exchange_boundary_conditions_with_neighbors(e)✅ Question 1.a:: What module command do you use to be able to use the fluent executable?
Put the answer to the above question here
✅ Question 1.b: Does fluent use shared memory parallelization, shared network parallelization, accelerators or a combination? Explain how you came up with your answer and provide links to any references.
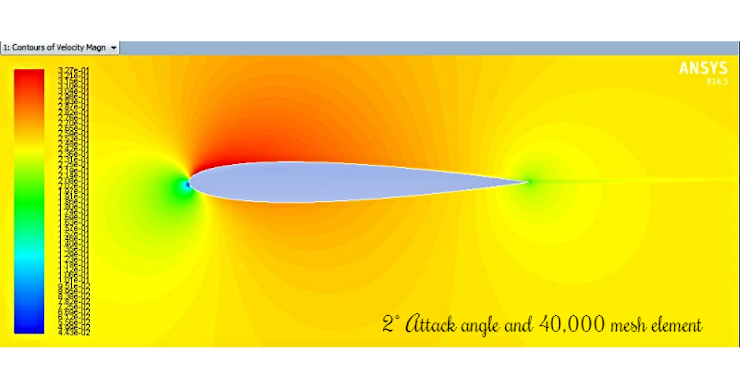
✅ Question 3.c: In the picture above the fluent mesh has 40,000 elements. Assuming this takes 0.001 seconds to solve the model (i.e. run solvemodel(e) once) for each element and 0.002 seconds to exchange boundary conditions (i.e. exchange_boundary_conditions_with_neighbors(e) once) for each element. Give a ballpark estimate for how long fluent will run on a single CPU for 10,000 time steps. Show how you came up with your estimate.
Put your answer to the above question here
✅ Question 3.d: The largest number of cores per node on the MSU HPCC is 96 and the largest number of cores any one user can use at once is 520. Estimate how long it would take to run the job described in Question 3.c using all of the resources available to a fluent on the MSU HPCC. Explain how you came up with your estimation.
Put your answer to the above question here
✅ Question 3.e: Fluent has a Graphical User Interface (GUI) for visualizing the results of a simulation. Most of our HPC is a Command Line Interface (CLI). Describe a procedure you could use to run fluent (or any program) and interact with it's GUI.
Put your answer to the above question here
One of of the core learning goals in this course is to help you understand the many ways you speed up your code. With code speed in mind, please answer the following questions.
✅ Question 4.a: Describe why you should assume that executing compiled code is always going to run faster than the same algorithm running in interpreted code?
Put your answer to the above question here.
✅ Question 4.b: Since compiled is always faster than interpreted explain why you would ever use an interpreted programming language?
Put your answer to the above question here.
✅ Question 4.c: In class we used "memory blocking" to speed up code by taking advantage of the memory cache. Actually computers have different levels of cache typically called L1, L2 and L3. L1 is faster than L2 which is faster than L3 which is faster than main memory. How big are the cache sizes on dev-intel18? HINT the hwloc commmand we used in class will also show memory sizes.
Put your answer to the above question here.
✅ Question 4.d: Given your answers to Question 4.b and a standard double is 8-bytes, what is a reasonable block size (i.e. how many doubles) could you use on the dev-intel18 node for the fastest L1 memory access? Explain how you came up with your answer.
Put your answer to the above question here.
✅ Question 4.e: Even though Memory is much faster than the network, explain when you should use shared network parallelization instead of shared memory parallelization?
Put your answer to the above question here.
Written by Dr. Dirk Colbry, Michigan State University

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.